이번 포스트는 딥 노스텔지아라고 알려진, Deep Fake의 일종인 프로젝트에 대해 알아보고자 합니다.
딥 노스텔지아는 무엇인지, 어떤 구조를 가지고 있는지에 대해 정리해 보도록 하겠습니다.
Deep Nostalgia라는 것이 널리 알려지게 된 계기는, MyHeritage사에서 정지된 이미지를 움직이는 이미지로 변환하는 서비스를 출시한 시점이라고 생각됩니다.
우선, 해당 서비스를 이용할 수 있는 링크는 다음과 같습니다.
MyHeritage Deep Nostalgia™, deep learning technology to animate the faces in still family photos - MyHeritage
www.myheritage.co.kr
회원가입을 진행하면 몇 가지 서비스를 제한된 범위 내에서 무료로 이용해 볼 수 있습니다.
그럼 본격적으로 Deep Nostalgia에 대해 알아보도록 하겠습니다.
MyHeritage가 2021년 초경에 Deep Nostalgia라는 AI 기반 서비스를 공개했는데, 이 AI가 수행하는 작업들을 딥 노스텔지어라고 통상적으로 부릅니다. Deep Nostalgia는 사진과 관련된 서비스를 제공하며, 2023년 2월을 기준으로 5가지의 기능을 제공하고 있고 제공하는 기능들에 관한 내용은 다음과 같습니다.
- Colorize Photos
흑백 사진에 적절한 색감을 부여하거나 색이 바랜 사진을 복구해 주는, 즉 뚜렷하게 채색해 주는 기능을 수행합니다.

- Enhance Photos
화질이 좋지 않은 사진을 뚜렷하게 만들어주는 기능을 수행합니다.

- Animate Photo
사람이 포함된 정지된 이미지에 어떠한 적절한 동작을 부여해 움직이는 이미지를 생성해 주는 기능을 수행합니다.

이미지 속의 여성을 타깃으로 하여 해당 여성이 취할 법한 동작을 부여하여 동영상으로 생성합니다. 결과물이 꽤 자연스러운 것을 확인할 수 있었습니다.
- Deep Story
사진과 사진에 대한 정보를 입력하면 해당 데이터에 해당하는 짧은 영상이 생성됩니다.

기본 소개 이외에 추가할 이야기를 설정하는 부분이 있으며, Text와 Image를 입력해 주면 추가적인 이야기가 생성됩니다. 다만, 추가하면 비용이 청구되므로 구체적인 테스트는 생략하도록 하겠습니다.ㅎ
- AI Time Machine
여러 장의 이미지(최소 10장을 권장)를 입력하고 이름을 지정해 줍니다. 그리고 과거 시대(Victorian, Viking, Roman, Pirate, 1950s 등)를 선택해 주면 해당 시대의 모습으로 변환해 줍니다.

2023년 2월 기준으로, 위 서비스는 무료로 제공되고 있진 않습니다.
위 기능들 중에서 주목을 받은 부분은 Colorize Photo와 Animate Photo입니다. 특히 Animate Photo가 큰 주목을 받았는데, 그래서인지 이를 기반으로 기능 확장을 진행한 것이 Deep Story와 AI Time Machine입니다. 결론적으로, 위 기술들은 모두 GAN을 기반으로 개발된 개발물들입니다.
GAN으로 생성되는 결과물들은 긍정적이든 부정적이든, 사회적으로 이슈가 되고 있습니다. 특히 Deep Fake를 통해 생성되는 결과물들은 “가짜 뉴스” 생성이나 개인정보 보호 등의 여러 문제들과 직면되면서 역기능으로 작용하는 사례가 많이 보고되고 있죠.
Deep Nostalgia는 이러한 역기능 속에서 순기능적으로 작용할 수 있도록 한 대표적인 사례로 뽑히고 있습니다. 아이디어 측면에서도 순기능적인 역할을 담당하지만, 데이터 보안 측면에서도 조금 다른 행보를 보이고 있기 때문입니다.
서비스를 공개한 MyHeritage는 이스라엘의 AI 기업인 D-ID가 제공한 AI 영상을 활용해 Deep Nostalgia를 개발했다고 합니다. 자세한 기술까지는 모르겠으나 D-ID가 개발한 안면 인식/식별/재현 솔루션을 활용하면 개인 정보 보호 및 데이터 보안을 지키면서 서비스를 제공할 수 있다고 합니다. 실제로 MyHeritage Site에서 생성한 결과물은 제 3자에게 공개하지 않으며 결과물이 악용될 우려가 있기에 말하는 모습은 제공하지 않는다고 합니다.
Deep Nostalgia의 내부 구조가 궁금하여 여러 자료를 찾아보았는데, 기술 공개 후 약 2년 정도 지난 시점이다 보니 이미 비슷한 기술들이 많이 공개되어 있었습니다.
Colorize Photo와 Enhance Photo 부분은 MicroSoft 및 DeOldify(→ SAGAN(Self-Attention Generative Adversarial Networks) 기반) 등의 자료를 찾아볼 수 있었고 Animate Photo의 경우는 2019년, 2022년 논문을 구현해 놓은 자료를 찾을 수 있었습니다. 그만큼 이제는 흔해진 기술이긴 하죠...ㅎㅎ
AI 영상 복원 (Colorize, Enhance Image)
MyHeritage사에서 Colorize 및 Enhance Photo를 구현할 때 DeOldify 프로젝트와 유사한 방식으로 구현했는지는 모르겠으나, 영상 복원 부분에서 SAGAN을 이용해 구현한 사례를 찾아볼 수 있으므로 SAGAN과 DeOldify에 대해 간단하게 정리해 보도록 하겠습니다.
- SAGAN
SAGAN은 앞서 언급했듯이 Self-Attention Generative Adversarial Network를 의미합니다. 그냥 쉽게 생각하면, Self-Attention을 GAN에 접목시킨 결과물이라고 생각하시면 될 것 같습니다.
전통적인 Convolutional GAN은 고해상도의 디테일을 저해상도 Feature Map에서의 부분적인 Local Points의 함수로만 만들었습니다. 이러한 구조는 GAN의 초기 연구 단계에서는 큰 성공을 이루어냈습니다. 그러나 이는 점차, Multi Class Dataset을 훈련시킬 때 특정 Image Class들에 대한 Modeling에 많은 어려움이 발생된다는 것을 알게 되었습니다.
SOTA ImageNet GAN Model들은 질감에 의해 구별되는 특징들(ex. 물결, 하늘, 풍경 등)을 합성하는 것에는 높은 성능을 보이는 반면 공간적인 특징이나 구조적인 패턴을 통해 구별되는 Class들에 대해서는 성능이 낮은 것을 확인할 수 있었습니다. 좀 더 쉽게 말한다면, 강아지를 생성했을 때 강아지의 털은 잘 생성해 내지만 발 또는 손과 같은 것들은 분리되지 못한 채 생성된다고 이해하시면 될 것 같습니다.
위 문제를 해결하기 위해서는 장기 의존성(Long-Range Dependency)을 처리해야 하는데, Convolution Network의 구조상 Local Receptive Field를 가지고 있기에 이미지에서 멀리 떨어진 부분에 대한 Dependency를 알기 위해서는 많은 Convolution Layer를 거쳐야 합니다. Convolution Kernel 크기를 늘려 네트워크 표현 용량을 증가시킬 수 있으나 이렇게 하면 Convolution 구조를 사용하여 얻은 계산 및 통계적 효율을 잃게 됩니다.
위와 같은 악순환적인 문제를 해결하기 위한 방법이 Self-Attention이며, 이는 장기 위존성 모델의 능력과 계산 및 통계 효율 사이에서 더 나은 균형을 이루게 해 줍니다. 따라서 이러한 특징을 GAN에 적용시키게 되면 전통적인 방식의 GAN에서의 문제점을 어느 정도 해결할 수 있게 됩니다.
Selft-Attention과 GAN을 합친 SAGAN은 전통적인 Convolution GAN과는 달리, 디테일을 모든 Feature Location으로부터 만들어 냅니다. 즉, 이미지의 모든 특성을 이용해 만든다는 것이죠.
다음은 SAGAN의 Self-Attention Module의 구조입니다.

Non-Local Model을 적용하여 Generator와 Discriminator가 효과적으로 멀리 떨어진 영역과의 관계를 Modeling 하게 해 줍니다. (참고로 x는 이전 Hidden Layer로부터의 Image Feature입니다.) Generator와 Discriminator는 Adversarial Loss의 Hinge Version을 최소화 함으로써 번갈아가며 학습되는 방식으로 Train 됩니다.
구조의 아주 작은 부분만 언급하긴 했으나, 대략적으로 이러한 원리를 통해 흑백 이미지에 컬러를 입힐 수 있게 됩니다. 공간적 경계를 유지한 채 Texture를 입히는 것, 이것이 SAGAN의 가장 자신 있는 분야니 까요ㅎ
SAGAN에 대해 전부를 다루기에는 너무 범위가 넓으니, 여기까지만 설명하도록 하겠습니다. 향후 시간이 된다면 SAGAN에 대해 정리해 보도록 하겠습니다.
- DeOldify
DeOldify는 Microsoft사에서 Deep Learning 방식을 이용해 색이 바랬거나 접은 자국, 약간 벗겨진 옛날 이미지를 복구하기 위해 진행한 프로젝트입니다.
지도 학습을 통해 진행된, 사진의 손상 정도가 복잡하거나 합성 이미지와 실제 이미지 사이의 Domain Gap이 큰 복구 작업의 경우 Network가 일반화되지 않는 문제가 발생되었습니다. Microsoft는 이를 해결하기 위해 대규모 합성 이미지 쌍과 실제 이미지를 활용한 새로운 Novel Triplet Domain Translation Network를 제안하였습니다.
오래된 이미지와 깨끗한 이미지를 각각 두 개의 잠재적 공간에 변환시키기 위해 두 개의 VAEs(Variational Autoencoders)에서 훈련시키는데, 이때 이 두 잠재된 공간 사이의 변환은 합성 데이터 쌍으로 학습됩니다. 이러한 변환은 실제 이미지에 일반화가 잘 되는데, 이는 Domain Gap이 Compact 한 잠재된 공간에서 잘 닫히기 때문입니다.
또한 스크래치 또는 얼룩과 같은 구조적 결함을 대상으로 하는 Non-Local Block과 노이즈 또는 색이 바랜 것과 같은 구조화되지 않은 결함을 대상으로 하는 Local Branch를 합쳐 Global Branch로 설계하였습니다. 이러한 두 개의 Branch는 잠재된 공간에서 융합되어 여러 결함이 있는 오래된 이미지를 복원하는데에서 좋은 성능을 보이게 되었습니다.
뭔가 좀 어렵게 설명되었는데, 다음 이미지를 통해 간단히 설명해 보겠습니다.
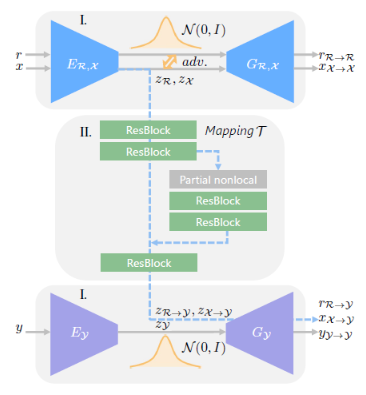
먼저, 두 개의 VAEs를 훈련시킵니다. 첫 번째 VAE는 실제 사진(r) 및 합성 이미지(x)에 대한 VAE이며, 이를 Adversarial Discriminator와 공동으로 훈련하여 Domain Gap을 좁히도록 합니다. 두 번째 VAE는 깨끗한 이미지(y)에 대해 훈련합니다. VAEs를 통해 이미지가 콤팩트한 잠재적 공간으로 변환됩니다.
그다음, Non-Local Block으로 손상된 이미지를 잠재된 공간의 깨끗한 이미지로 Mapping 하는 것을 학습합니다.
자세한 내용은 많이 생략되긴 했지만, 결론적으로는 손상된 이미지를 통해 어떠한 합성 이미지를 생성하고 이 둘의 Gap으 줄입니다. 그리고 이를 다시 깨끗한 이미지와 비교해 합성 이미지를 깨끗한 이미지로 생성될 수 있도록 하는, 전형적인 GAN의 형태를 띠고 있습니다. 이와 같은 과정을 통해 Enhanced Image를 생성하는 거겠죠.ㅎ
이것 또한 자세히 다루기엔 범위가 넓으니 여기까지만 다루도록 하겠습니다.ㅎ
Animate Image
HyHertiage사에서 발표한 Animate Photo의 경우도, 구현 자료를 찾을 수 없어 구체적으로 어떻게 구현했는지는 알 수 없으나 비슷한 사례를 Github에서 찾아볼 수 있었기에 해당 부분에 대해 짧게 정리해보고자 합니다.
우선, 참고한 Github 링크는 다음과 같습니다.
GitHub - yoyo-nb/Thin-Plate-Spline-Motion-Model: [CVPR 2022] Thin-Plate Spline Motion Model for Image Animation.
[CVPR 2022] Thin-Plate Spline Motion Model for Image Animation. - GitHub - yoyo-nb/Thin-Plate-Spline-Motion-Model: [CVPR 2022] Thin-Plate Spline Motion Model for Image Animation.
github.com
Thin-Plate Spline Motion Model이라고 명칭 된 이 논문은 비지도 모션 변화 Framework를 제안했습니다. 이는 Source Image(= 정적인 이미지)와 움직이는 이미지 사이의 큰 Pose Gap에서 비지도 학습 방식으로 임의의 객체에 움직임을 부여하는 Model들이 좋은 성능을 보이고 있지 않기 때문에 개발하게 되었다고 합니다.
Input Image의 Feature Map들을 움직이는 Image의 Feature Domain으로 Warp 하는,더욱 유연한 Optical Flow를 생성하고 누락된 영역을 보다 사실적으로 복구하기 위해 Multi-Resolution Occlusion Mask를 활용하여 효과적인 Feature 융합을 달성하였다고 합니다. 게다가 추가적인 보조 Loss Fuction은 Network Module에 명확한 분업을 수행할 수 있도록 설계하여 고품질의 이미지를 생성할 수 있도록 하였다고 하네요.
결론적으로 위와 같은 방식을 통해, 말하는 얼굴, 사람의 움직임과 Pixel 애니메이션 등과 같이 다양한 Object에게 움직임을 부여할 수 있다고 합니다.
우선, 전반적인 구조는 다음과 같습니다.
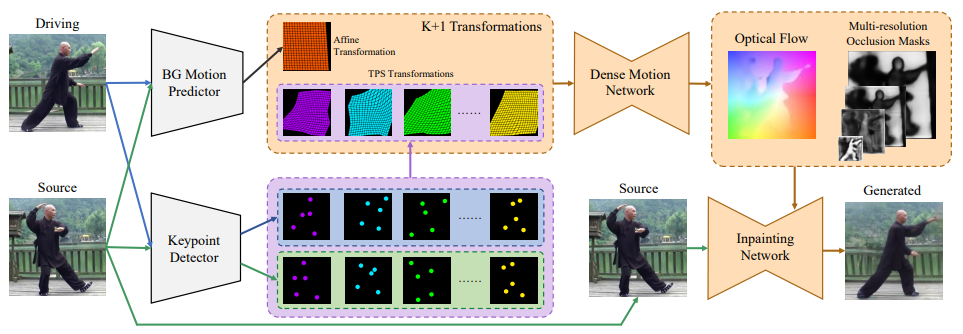
BG Motion Predictor는 Source Image에서 Driving Image로 Background Motion을 나타내는 Affine Transformation을 예측합니다. 동시에 KeyPoint Detector를 통해 각각의 TPS transformation을 생성하는 K Set들의 Keypoints를 추정합니다.
이후 Dense Motion Network가 Optical Flow와 Multi-Resolution Occlusion Masks를 추정하기 위한 K+1 Transformation들(= K TPS Transformations와 한 개의 Affine Transformation)을 합칩니다. 마지막으로 Source Image를 Inpaining Network에 넣고 Optical Flow를 사용하여 Encoder에서 추출한 Feature Maps을 Warp 하고 이들을 해당 해상도 Occlusion Masks로 Masking 합니다. 그러면 Inpaining Network의 최종 Layer가 Output Image를 생성해 낼 것입니다.
뭔가 복잡하긴 한데, 좀 풀어쓰면 다음과 같습니다.
Driving Image에서는 배경과 관련된 어떠한 변환 값들을 추정하고 Source Image에서는 Object의 Motion 값을 추정하여 TPS 변환 값을 추출합니다. 이러한 값들을 통해 Source Image속의 Object를 Driving Image의 Object와 같은 Motion을 취하도록 왜곡시켜 어떠한 중간 단계의 이미지로 만듭니다. 이 중간 단계 이미지들은 변환 및 왜곡 때문에 빈 공간들이 생기게 될 것입니다. 이들을 적절히 채워주기 위해 Optical Flow와 Multi-Resolution Occlusion Mask를 추정하는 것이고 잘 추정된 값들은 빈 공간을 적절히 잘 채우게 되어 마치 Source Image가 Driving Image와 같은 Motion을 자연스럽게 취하는 것과 같은 결과 값을 만들어낼 수 있는 것입니다.
중간중간 등장하는 TPS나, Dense Motion Network, Inpaingin Network와 같은 내용은 설명하기엔 너무 길어져서 생략하도록 하겠습니다. 이번 포스트에서는 그냥 아... 대충 이렇게 구성되는구나 정도만 이해해도 될 것 같습니다.
이와 같이 Deep Nostalgia가 어떤 프로젝트인지, 구체적으로 어떻게 구성되었는지, 어떤 기술들을 이용하였는지에 대해 짧게 알아보았습니다. 각각의 기술들이 그리 만만한 기술들은 아니기에 깊게 다루진 못했지만, 향후 기회가 된다면 정리하고 넘어가는 것도 좋을 것 같습니다.
이번 포스트는 여기서 마무리하도록 하겠습니다.
'Programming > Computer Vision' 카테고리의 다른 글
| [OpenCV] Landmark를 이용한 Face Mapping 수행 (0) | 2023.02.16 |
|---|---|
| [Pose Estimation] 2D/3D Pose Estimation에 관한 내용 (0) | 2023.02.15 |
| [OpenCV] 특정 영역 지정 후 해당 영역에서 이미지 비교 (0) | 2023.02.02 |
| [OCR] [Tesseract - 4] Tesseract로 OCR 수행 후 특정 Text 추출 (0) | 2023.01.18 |
| [OCR] [Tesseract - 3] Image Processing 진행 후 Tesseract로 OCR 수행 (1) | 2023.01.17 |




댓글