이번 포스트에서는 Everybody Dance Now라는 프로젝트 명으로 소개된 논문을 다뤄보고자 합니다.
OpenPose를 통해 Pose를 추정하고 GAN을 기반으로 하여 추정된 Pose를 수행하는 어떠한 Image들을 생성해내는 논문이 2019년도에 소개되었습니다.
해당 논문을 처음 보게 된 것은 2022년도였는데, 지금 포스팅을 하게 되었네요. 아무튼 논문에 대해 간단히 알아보고 실제 수행해보도록 하겠습니다.
다룰 논문(프로젝트) 링크는 다음과 같습니다.
URL : https://carolineec.github.io/everybody_dance_now/
Everybody Dance Now
Everybody Dance Now This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing, we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing stand
carolineec.github.io
우선, Everybody Dance Now 논문은 GAN을 기반으로 한 내용입니다. 따라서 GAN에 대해 아주 간단하게 설명한 내용을 참고해 주세요.
[DL] GAN(Generative Adversarial Network)이라는 것에 대하여.
Deep Learning Network의 종류 중의 하나인 GAN에 대해서 정말 간략하게 설명하고자 합니다. GAN이란, Generative Adversarial Network의 약자로 적대적 생성 신경망이라고 합니다. 단어가 좀 애매하지만, 결론적
mj-thump-thump-story.tistory.com
GAN이라는 것에 대해 대략적으로 알고 있다는 가정하에 본격적으로 논문에 대한 전반적인 내용을 설명해보도록 하겠습니다.
우선 "Everybody Dance Now"는 어떠한 Motion이 담겨있는 Source Video를 Input으로 주면 해당 Source의 Motion을 Target에 적용하여 Output 하는 기술입니다. 이때 Target Image에는 어떠한 Person이 속해져 있으며 Source Video의 Motion 정보를 담고 있지 않습니다.

위 이미지에서 여성 발레리나의 동작이 담겨 있는 Source Video를 DL Model에 제공하면 아래의 남성이 해당 모션을 동작하는 결과를 얻을 수 있습니다. 이때 남성 이미지의 원본은 발레리나의 동작을 수행하던 영상이 아닙니다.
해당 논문은 두 가지의 방향을 가지고 있습니다. 하나는 안정적인 Pose Estimation이고 다른 하나는 현실성 높은 이미지와 이미지 사이의 변환입니다. Pose Estimation에서는 OpenPose, DensePose와 같은 바르고 안정적인 방식을 지향하며, imageTOimage는 pix2pix, CoGAN, UNIT, CycleGAN, DiscoGAN, Cascaded Refinement Network, pix2pixHD와 같은 high-quality single image 생성 모델을 지향합니다.
Everybody Dance Now는 Pipeline이 3 Stage로 나누어져 있습니다. (pose detection, global pose normalization, normalized pose stick figures를 target subject에 mapping)
Pose Detection Stage에서는 Source Video로부터의 Pose Stick Figure를 생성하기 위해 Pre-Trained Pose Detector를 사용합니다. 다음으로 Global Pose Normalization Stage는 Source Video와 Target Video Frame안에서의 체형과 위치의 차이를 처리합니다. 마지막으로 적대적 학습을 통해 Target Person의 Pose Stick Figure로부터 Mapping 하는 법을 배우도록 시스템을 설계합니다.
세 가지 단계의 모습은 다음 그림과 같습니다.

P : pose detector
G : mapping
D : 적대적 판별자 (adversarial discriminator)
Norm : normalization process
Training 부분에서는, P가 target subject의 video frame으로부터 pose stick figure를 생성합니다. 그리고 D를 통해 G를 학습합니다. 이때 D는 실제 $(x_t, x_{t+1}), (y_t,y_{t+1})$과 가짜 $(x_t, x_{t+1}), G((x_t)),G((x_{t+1}))$ sequence사이의 구별을 시도합니다.
Transfer 부분에서는, Source person에서 Target person의 joint로 변환되는 Source person의 pose joint를 얻기 위해 P를 사용합니다. 이때 변환은 Norm에 의해 수행된 것입니다. 이후 학습된 G를 적용합니다.
위의 과정을 좀 더 풀어서 설명하면 다음과 같습니다.
- Pose Encoding
Pre-Trained Pose Detector인 P를 이용해 Image Frame으로부터 2D Pose를 Estimation 한 후 Colored Pose Stick Figure를 만들어냅니다.
- Global Pose Normalization
Source Video와 Target Video에서 각각의 Subject는 다른 신장 크기를 가지고 있을 것이며 Camera에 비치는 위치 값도 모두 다를 것입니다. 따라서 두 Subject 간에 re-targeting을 해주어야 합니다. 이것을 Transfer 과정이라고 하며, 이의 과정은 다음과 같습니다.
Norm은 Skeleton의 키와 발목 위치를 분석하여 가장 가까운 발목과 가장 먼 발목 위치 간의 Linear Mapping을 사용해 수행합니다. (Image 상에서의 Subject는 촬영한 Camera의 위치가 모두 다르고 사람의 비율 등이 모두 다릅니다. 따라서 Mapping 시키기 위해 Pose KeyPoints를 변환시켜 Target Image의 Person에 맞춰 줍니다.)
- Pose to Video Translation
Everybody Dance Now Project에서, 영상 합성 방법은 adversarial Single Frame Generation 과정을 기본으로 합니다. Generation Network인 G는 Multi-scale Discriminator인 D, 즉 $D = (D_1, D_2, D_3)$에 대항하여 Min Max Game을 진행합니다. GAN의 기본 개념처럼 서로 적대적인 상호작용을 하여 G는 이미지들을 잘 합성하여(Pose Stick Figure가 주어지면 해당 값을 기준으로 한 사람의 이미지를 합성) D를 속이게 됩니다.
- Temporal Smoothing & Face GAN
Video Sequence를 만들어내기 위해 Single Image Generation setup을 수정해 인접한 Frame사이의 밀접함을 증가시킵니다. 즉 각각의 Frame을 만들어내는 대신, 두 개의 연속적인 Frame을 예측하는 방식으로 생성합니다.
faceGAN을 이용해 디테일을 살리고 얼굴을 좀 더 현실적으로 만듭니다.

Generator G로 이미지를 생성한 후, 이미지의 작은 부분 $G(x)_F$를 넣고 같은 방법으로 Pose Stick Figure $x_F$를 또 다른 Generator $G_f$에 넣습니다. 이 $G_f$를 거치게 되면 residual r = $G_f(x_F, G(x)_F)$가 되는데 이를 $G(x)_F$와 더해 최종적으로 합성된 얼굴을 생성합니다. 이러한 합성이미지를 GAN을 이용해 진짜와 가짜를 구별하는 과정을 반복해 학습합니다. (Face관련 discriminator = $D_f$)
위 내용이 Everybody Dance Now의 전반적인 내용입니다. 세부 내용은 많지만, 이 논문이 대략 어떻게 수행되는지에 대해서 대략적으로 이해하기 위한 내용만 다루었습니다.
이제, 논문 내용을 어느 정도 알게 되었으니 Test를 본격적으로 진행해보도록 하겠습니다.
다음과 같은 순서로 진행할 수 있습니다.
1. Source Video와 Target Video 선정

Source Video는 어떠한 동작을 하는 Video이고 Target Video는 Source Video와 같은 동작을 하게끔 만들고 싶은 Video입니다. 이때 Target Video는 Source Video에서의 동작을 수행하지 않아도 됩니다.
2. Source Video에서 Skeleton Bone 추출 및 Face Detection 수행
Source Video에서 일정 Term을 두고 Image Frame을 추출합니다. 그리고 Face를 Detection 하고 해당 영역을 Crop 하여 저장합니다. 또한 Image Frame에서 Pose를 추출하여 .npy 파일로 저장합니다.
3. Target Video에서 Skeleton Bone
2번 과정과 마찬가지로 Video에서 image Frame을 추출하여 Pose Data와 Face Image Data를 추출한 후 각각을 저장합니다.
4. Generator와 Discriminator를 학습 진행
수행결과 D에 해당하는 Train결과와 G에 해당하는 Train 결과가 저장됩니다. (Image 생성 학습 및 Image 판별 학습 결과)
5. Normalization 수행
Source와 Target Image의 몸매, 위치 등의 차이를 계산하여 Normalize 시킵니다. (2개의 Skeleton Size를 normalization)

6. Transfer 수행
최종적으로 변환을 수행합니다. 결과물은 다음과 같습니다.


해당 결과물이 Face GAN 및 Temporal Smoothing과정이 생략된 결과물이긴 하나, 생성된 Image의 퀄리티가 그다지 좋아 보이지는 않습니다. 손 부분이 잘린 부분과 간혹 비 정상적인 구조가 생성되기는 하지만 전반적으로 동작을 잘 따라 하는 편입니다.
이번에는 Source Video는 일정하다는 가정하에, Target Video만 변경될 경우, 소요되는 과정 및 결과에 대해 알아볼 것입니다. 결과는 다음과 같습니다.
우선 Target Video에서 Frame 추출 및 Bone 추출 후 학습하는 과정이 3분짜리 비디오를 기준으로 약 4시간 정도 소요됩니다. 이후 Generator 및 Discriminator 학습에는 약 4시간 이상이 소요되고, Normalization 처리에는 약 1시간 정도 걸립니다. 마지막으로 Image 변환 과정은 약 2분 정도 소요됩니다.
초기 Source Video에서 Frame을 추출 및 Bone 추출과정 (3분 비디오 기준 약 1시간 40분 소요)만 제외하고는 Target Video가 변경될 때마다 위 과정들을 수행해 주어야 합니다. 또한 FaceGAN 및 Smoothing 과정을 추가적으로 수행하려면 더 많은 시간이 필요합니다.
다른 Target Video로 Test 한 결과는 다음과 같습니다.

Target Video의 배경이 단순해지니 이전에 Test 해보았던 결과물보다 배경 부분에서는 좀 더 자연스러워졌습니다. 하지만 여전히 Image가 깨지는 것과 같은 결과는 동일합니다.
Source Video를 변경하지 않고 Target Video만 변경할 경우 총 약 16시간 정도 소요되는 것 같습니다. (NVIDIA GeForce GTX 1060 3GB 기준)
이제까지 Test 한 결과물이 아주 만족스러운 결과는 아닙니다. 결과 영상을 생성하였다는 기준으로는 성공이지만 프레임이 깨지고 부자연스러운 부분이 많다는 점에서는 말이죠.
이번에는 얼굴 부분을 좀 더 자연스럽게 만들기 위한 Face Enhancement 부분 기능을 추가하여 Test 해 볼 것입니다.
우선 Face Enhancement는 다음과 같은 방식을 통해 구현하였다고 합니다.
Face GAN이라는 것을 이용해 얼굴의 Realistic을 강조하였습니다.

Residual(잔차)은 Generator $G_f$에 의해 예측되며 Main Generator로부터 원본 얼굴 예측에 가중됩니다.
좀 더 자세히 풀어쓰면, Generator G로 이미지를 만들어낸 후 이미지의 작은 부분(얼굴 부분) $G(x)_F$를 넣습니다. 그리고 같은 방식으로 Pose Stick Figure의 얼굴 부분 $x_F$를 또 다른 Generator $G_f$에 넣습니다. 즉, Pose Stick Figure의 얼굴($x_F$)과 G(x)의 얼굴 부분을 합쳐서 $G_f$에서 Generator 하게 됩니다.
$G_f$를 거치게 되면, Residual $r = G_f(x_F, G(x)F)$이 나오게 되고 이를 G(x)의 얼굴 부분 $G{f(x)}$와 결합하여 $r + G(x)_F$인 최종적으로 합성된 얼굴이 나오게 됩니다. 그리고 이러한 합성이미지를 Discriminator $D_f$가 진짜와 구별하는 학습을 진행하게 됩니다.
위와 같은 방식을 적용하여 Face Enhancement를 수행한 결과물은 다음과 같습니다.
초반 결과물은 다음과 같습니다.

그리고 다음은 학습을 어느 정도 시킨 후의 결과물입니다.

초반에 뭉그러져있던 얼굴이 GAN을 거친 이후에는 조금 펴져있는 편이긴 합니다. 그러나 최종 결과물을 보면 눈에 확연하게 좋아진 부분은 없어 보입니다.

대략적으로 Face GAN의 학습시키는 시간은 약 12시간 정도 걸리는 것 같습니다. (Batch 40000일 경우)
긴 시간 학습을 시켰으나 그리 효과적이지는 않습니다...
마지막으로 Frame과 Frame 사이의 연관성을 부여하여 좀 더 부드러운 결과물을 만들어내기 위한 과정인 Temporal Smoothing을 적용하여 Test를 진행해 봅니다.
앞서 전반적인 EverybodyDanceNow를 설명하면서 언급했던 부분이긴 하나, 다시 한번 Temporal Smoothing 부분만 정리해 봅니다.
GAN을 이용해 Single Frame을 개별적으로 생성시키게 되면 첫 번째 Frame과 두 번째 Frame이 따로 생성되기 때문에 연속성이 저하될 수 있습니다. 때문에 Temporal Smoothing 기법을 통해, 연속적인 비디오 시퀀스를 만들어내기 위해서, 저자들은 single image generation setup을 수정하여 인접한 프레임 사이의 밀접함을 증가시켰습니다. 즉, 각각의 프레임을 만들어내는 것 대신에, 두 개의 연속적인 프레임을 예측하는 방식을 사용한 것이죠.
First Output $G(x_{t-1})$은 First Output과 연관 있는 Pose Stick Figure $x_{t-1}$과 Zero Image $z$의 조건이 충족된 값입니다. 이때 Zero Image는 Time이 $t-2$일 때 이전에 생성된 Frame이 없을 때의 Placeholder입니다.
Second Output $G(x_t)$는 Second Output과 연관있는 Pse Stick Figure $x_t$와 First Output $G(x_{t-1})$의 조건이 충족된 값입니다. 즉, 독립적이지 않게, 이전의 Output을 이용하여 다음의 Output을 계산합니다.
결과적으로 Discriminator는 Real Sequence $(x_{t-1}, x_t, y_{t-1}, y_t)$와 Fake Sequence $(x_{t-1}, x_t, G(x_{t-1}), G(x_t))$ 사이의 차이를 계산하여 판단합니다. Temporal Smoothing 변화들은 업데이트된 GAN Objective에 반영됩니다.
이에 대한 objective는 다음과 같습니다.
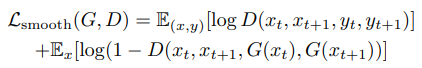
이 Temporal Smoothing 및 FaceGAN을 적용한 결과물은 다음과 같습니다.

여전히 몸이 끊기는 현상은 발생됩니다. Smooth를 위한 Train과정이 추가되므로 시간 소요가 추가되는 것이기 때문에 시간 대비 큰 효과는 없어 보입니다.
정확한 이유는 모르겠으나, 소개된 결과물과 실제 테스트해본 결과물의 퀄리티 차이가 상당히 심합니다. 특히 배경 부분에 서서 Frame이 이어지지 않는 문제가 논문에서 발표한 영상과 차이가 심하죠.
원인은 정확히 모르겠습니다. 다만, 찾아보니 퀄리티 차이가 대체적으로 나타나는 것 같긴 합니다. 뭔가 이유가 있겠죠...?
여기까지, Everybody Dance Now 논문과 관련된 작업을 수행해 보았습니다.
영상 2개를 이용해 하나의 영상을 따라 하는 다른 하나의 영상을 만들어 낼 수 있다는 것이 새로웠습니다. 놀랍기도 했고요. 시간이 많이 걸리기에 Real-Time으로 무엇인가를 하는 것은 불가능해 보이지만, 기술 자체를 놓고 보았을 때 활용 분야가 꽤 많을 것 같다는 생각은 들었습니다.
아마 계속 Develop 되겠죠?ㅎ
조금 아쉬운 결과를 얻게 되긴 하였으나, 이번 포스팅은 여기서 마무리하도록 하겠습니다.
'Programming > Computer Vision' 카테고리의 다른 글
| [SLAM] EuRoC를 이용한 ORB-SLAM3 테스트 (0) | 2023.01.11 |
|---|---|
| [SLAM] ORB SLAM과 SLAM Dataset에 관한 정리 (0) | 2023.01.11 |
| [Image Comparison] 두 이미지의 일치율 비교 (0) | 2023.01.06 |
| [ZED2] ZED2 카메라를 Unity에서 사용하는 방법 (0) | 2023.01.05 |
| [DeepFake] DeepFake 기술과 간단한 예제 수행 (0) | 2023.01.05 |




댓글