Object Detection, Keypoint Detection, 이외의 Prediction 및 Classification 기능을 수행하는 AI를 개발할 때 많이 활용되는 구조인 ResNet에 대해 다뤄볼 예정입니다.
ResNet으로 널리 알려진 이 구조는 2015년 MicroSoft에서 개발한 알고리즘으로 정식 게재된 논문 명은 “Deep Residual Learning for Image Recognition”입니다. 2014년 GoogLeNet이 22개의 층으로 구성된 것에 비해 ResNet은 152개의 층을 가진다. 7배 깊어진, 급속도로 깊어진 Model입니다.
ResNet에 대한 논문은 다음 링크에서 확인할 수 있습니다.
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
2015년 당시 기준으로 ILSVRC에서 우승한 알고리즘의 에러율들은 다음과 같습니다.

ResNet이 Error가 적은 것을 확인할 수 있으며 사람의 평균 에러율이 5인 것과 비교하면 ResNet은 성능이 좋은 Model인 것임을 알 수 있습니다.
특히, 위 그래프를 보면 ResNet이 다른 Model들 보다 Network 깊이가 월등히 깊으며, 이는 Network의 깊이가 깊어지면 Top-5 Error가 낮아진다는 것을 의미하기도 합니다. 그런데 단순히 Network의 깊이가 깊어지면 성능이 좋아질까요?
ResNet 논문을 참고하면 다음과 같은 Convolution Layer와 Fully-Connected Layer들로 20층의 Network와 56층의 Network를 각각 만들어 성능을 테스트한 결과를 확인할 수 있습니다.

56층을 갖는 Network가 20층을 갖는 Network 보다 성능이 나쁘다는 것을 확인할 수 있습니다. 즉, Network를 무조건 깊게 한다고 좋은 것은 아니라는 것을 나타내는 것이죠. 따라서 ResNet 논문 저자들은 다음과 같은 방식을 통해 Network를 구성하였습니다.
ResNet의 핵심 기술이라고 생각될 수 있는 요인 중 하나는 Residual Block입니다. (논문의 타이틀에도 언급되어 있을 정도로...) 이 Residual Block은 간단히 표현하면, 입력 값을 출력 값에 더해줄 수 있도록 하는 Shortcut 역할을 담당하는 것입니다.

위 이미지의 왼쪽 부분은 Plane Layer, 즉 기존의 방식에서 사용하던 구조이고 오른쪽 부분은 Residual Block 구조를 나타낸 것입니다.
두 구조의 차이점은 동일한 연산을 진행하고 난 후, Input인 x를 더하는지 그렇지 않는지에 있습니다. 단순히 Input x를 더하는 것만으로 Layer는 Direct로 학습하는 것 대신, Skip Connection을 통해 각각의 Layer들이 작은 정보만을 추가적으로 학습할 수 있도록 할 수 있습니다. 즉, 기존에 학습된 x를 추가함으로써 x만큼을 제외한 나머지 부분, F(x)만을 학습하면 되기 때문에 학습량이 상대적으로 줄어드는 효과가 있습니다.
- Plain Layer
Layer의 Output인 Feature Vector(Feature Map)을 y라고 할 때, y = F(x)로 표현할 수 있습니다. 이때 y는 x를 통해 새롭게 학습하는 정보를 의미합니다. (= 기존에 학습한 정보를 보존하지 않고 변형시켜 새롭게 생성하는 정보)
Neural Network가 고차원적인 Feature Vector로의 Mapping을 학습한다는 개념으로 생각했을 때, 층이 깊어질수록 한 번에 학습해야 할 Mapping이 너무 많아지기에 학습이 어려워진다는 문제가 발생될 수 있습니다.
- Residual Block
y = F(x) + x로 표현할 수 있으며, 이때의 y는 x가 그대로 보존되므로 기존에 학습한 정보를 보존하고 거기에 추가적으로 학습하는 정보를 의미합니다. Output에 이전 Layer에서 학습했던 정보를 연결함으로써 해당 층에서는 추가적으로 학습해야 할 정보만을 Mapping, Learning하게 됩니다.
학습이 진행되어 Layer의 깊이가 깊어질수록 x는 출력 값이 H(x)에 근접하게 되어 추가 학습량 F(x)는 점점 작아지게 됩니다. 따라서 최종적으로는 0에 근접하는 최소 값으로 수렴되어야 합니다. 즉, H(x) = F(x) + x에서 추가 학습량에 해당하는 F(x) = H(x) - x가 최소 값(= 0)이 되도록 학습이 진행되며, H(x) = F(x) + x이므로 단순히 입력에서 출력으로 연결되는 Shortcut만 추가하면 되기에 네트워크 구조 또한 크게 변경할 필요가 없습니다. 또한 입력과 같은 x가 그대로 출력에 연결되기에 Parameter 수에 영향이 없으며 덧셈 연산이 늘어나는 것을 제외하면 Shortcut 연결을 통한 연산량 증가는 없습니다. 이때 H(x) - x를 잔차(Residual)라고 하며 이 때문에 ResNet이라고 명명되었습니다.
전반적인 ResNet의 구조는 다음과 같습니다.

기본적으로 ResNet은 VGG-19의 구조를 뼈대로 갖습니다. 이 기본적인 구조에 Convolution Layer 등을 추가하여 깊게 만든 후, Shortcut들을 추가하는 구조입니다. 34층의 ResNet은 처음을 제외하고는 균일하게 3x3 Convolution Filter를 사용하였으며 Feature Map의 Size가 반으로 줄어들 때, Feature Map의 Depth를 2배로 높였습니다.
다음은 ResNet의 여러 핵심 기술에 대한 내용입니다.
- Residual Block
ResNet에서는 2개 이상의 Convolutional Layer와 Skip-Connection을 활용하여 하나의 Block을 만들고 이 Block을 쌓아서 Network를 만듭니다. 이때 하나의 Block에 해당되는 구조와 수식은 다음과 같습니다.

Residual Block은 l번째 Block으로 $x_{l}$을 입력으로 받고 Skip-Connection인 $h(x_{l})$과 Convolutional Layer $F(x_{l}, W_{l})$를 통과한 결과의 합으로 $y_{l}$을 출력합니다. 해당 출력을 활성함수에 통과시키면 다음 블록의 입력 $x_{l+1}$이 됩니다.
- Pre-activation
ResNet에서 사용하는 Activation함수는 ReLU이며, shortcut된 신호와 합쳐지는 곳 뒤에 위치합니다. 논문의 저자들은 아래와 같이 여러 구조들을 실험하였다고 합니다. 각각의 구조들을 CIFAR-10 Dataset을 이용해 학습시킨 후 Test Set에서의 Error를 측정하였으며, 결과는 다음과 같습니다.

- (a) 구조
ResNet 논문에서 제안된 가장 기본적인 구조이며, Shortcut된 신호와 합쳐지는 Addition 연산 뒤에 ReLU함수를 통과시키는 구조입니다.
- (b) 구조
(a) 구조에서의 Batch Normalization을 Addition 연산 뒤로 옮긴 구조입니다. 학습결과는 Original 형태보다 나빠졌습니다.
- (c) 구조
Activation함수 ReLU를 Weight Layer안으로 옮겨 ReLU를 통과한 신호를 Shortcut 한 신호와 합치는 구조입니다. 해당 구조는 잔차를 학습할 때 신호 값의 범위가 양수가 되어 Forward Propagation시에 신호가 양수로 편향되는 문제가 있습니다. 때문에 네트워크 표현력이 낮아져 성능이 나빠집니다.
- (d) 구조
논문 저자들은 ResNet에서 신호 범위가 양수가 아닌 전체 실수 영역 ($-\infty ~ +\infty$)을 가져야 한다고 예상하였고 이 생각을 바탕으로 설계된 구조입니다.
ReLU만 Weight 앞에 위치시킨 구조로 기본적인 구조보다 성능이 좋지 않은 것을 확인할 수 있습니다.
- (e) 구조
(d) 구조와 마찬가지로 전체 실수 영역을 가지도록 설계한 구조로, Batch Normalization과 ReLU 모두 Weight 앞에 위치한 Full Pre-Activation 구조입니다. 가장 성능이 좋은 구조입니다.
(d), (e) 구조들은 비대칭적인 구조로 신호가 Weight Layer를 먼저 통과하는 구조가 아닌 Activation(= ReLu, Batch Normalization) 앞에 위치시키는 구조입니다. 즉, Pre-Activation 구조가 성능이 좋다는 결과를 얻어 Activation 함수가 Weight Layer를 거쳐가는 신호에만 영향을 주도록 왼쪽 구조를 가운데 구조로 변경하였습니다. 이후, 동일한 구조에서 Residual Unit의 영역을 수정하여 Pre-Activation 구조를 설계하였습니다.

결과적으로 Pre-Activation 구조가 Post-Activation 구조보다 성능이 좋다는 결과를 얻었다고 합니다. 특히, 층이 깊어질수록 Pre-Activation 구조가 좋은 성능을 보인다고 합니다.
- Bottleneck
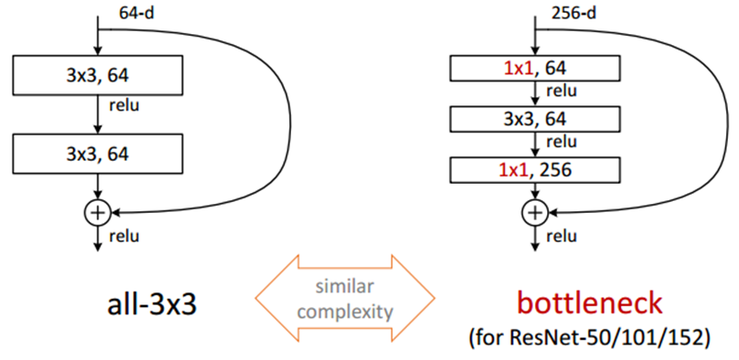
우선, Residual Block은 1x1, 3x3, 1x1로 위 이미지의 오른쪽과 같은 구성으로 이루어집니다.
이를 Bottleneck 구조라고 하는 이유는 차원을 줄였다가 뒤에서 다시 차원을 늘리는 것이 병목처럼 보이기 때문에 붙여진 이름입니다. 이러한 구조를 사용하는 이유는 연산 시간을 단축시키기 위해서입니다.
처음 1x1 Convolution은 NIN(= Network-in-Network)이나, GoogLeNet의 Inception 구조과 같이 차원을 줄이기 위한 목적의 연산입니다. 마지막 1x1 Convolution은 다시 차원을 확대시키는 역할을 담당합니다. 결과적으로 3x3 Convolution 2개를 곧바로 연결시킨 구조에 비해 연산량을 감소시킬 수 있습니다.
예를 들어 설명하면, 위 이미지의 왼쪽 Bottleneck을 사용하지 않은 경우 고려해야 할 Parameter의 개수는 3x3x64x2 = 1152이지만, Bottleneck을 사용할 경우 (1x1x64) + (3x3x64) + (1x1x256) = 896으로 Parameter 개수가 줄어들게 됩니다.
위와 같은 특징을 가진 ResNet은 현재 많은 DL Model들에 활용되고 있습니다. (→ ResNet-18, ResNet-50, ResNet-101, ResNet-200 등, 이때 뒤의 숫자는 네트워크 계층의 수를 의미합니다.)
특히 Skip-Connection과 같은 아이디어는 많은 Model들에 좋은 영감을 주는 구조라고 합니다. 많은 AI 관련 프로그램들의 내부를 보면 ResNet이 심심치 않게 등장하긴 하죠ㅎ
이번 포스트는 간단하게, 이렇게 마무리하도록 하겠습니다.
아주 기본이 되는 구조인 만큼 활용도도 높으니 알아두면 좋을 것 같습니다.
'Programming > Deep Learning Network' 카테고리의 다른 글
| [Model] FPN (0) | 2023.02.22 |
|---|---|
| [Model] RetinaNet (0) | 2023.02.22 |
| [Model] MobileNet v1 (0) | 2023.02.21 |
| [Model] Grad-CAM (1) | 2023.02.15 |
| [Deep Learning] GAN(Generative Adversarial Network)이라는 것에 대하여. (0) | 2023.01.09 |




댓글