이번 포스트는 Pose Estimation과 관련된 논문 중 하나인, VNect과 XNect이라는 것에 대해 다뤄보도록 하겠습니다.
해당 논문은 RGB 카메라를 통해 사람의 자세를 추정하는 방법을 다룬 것입니다.

우선, 각 논문은 다음 링크를 참조해 주세요.
- VNect (Real-Time 3D Human Pose Estimation With A Single RGB Camera)
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
We present the first real-time method to capture the full global 3D skeletal pose of a human in a stable, temporally consistent manner using a single RGB camera. Our method combines a new convolutional neural network (CNN) based pose regressor with kinemat
arxiv.org
- XNect (Real-Time Multi-Persion 3D Motion Capture With A Single RGB Camera)
XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates successfully in generic scenes which may contain occlusions by objects and by other people. Our method operates in subsequent stages. T
arxiv.org
VNect과 XNect에 관한 내용을 다루기 이전에, 우선 Pose Estimation이라는 것이 무엇인지에 대해 잘 모르신다면 다음 포스트를 참조해 주세요.
[Pose Estimation] 2D/3D Pose Estimation에 관한 내용
Computer Vision과 관련된 AI, Deep Learning 분야에서 거의 필수적으로 다루는 주제가 있습니다. 바로 Pose Estimation인데요. 이번 포스트에서는 이 Pose Estimation에 관한 내용을 다루고자 합니다. Pose Estimation
mj-thump-thump-story.tistory.com
그럼 이제 본격적으로 각 논문을 다뤄보도록 하겠습니다.
논문이 작성된 순서대로 VNect → XNect의 순서로 진행하도록 하겠습니다.
VNect
Real-Time 3D Human Pose Estimation with a single RGB camera라는 Title을 가진 논문입니다.

위 이미지와 같이 단일 RGB 카메라를 이용해 이미지에 있는 한 사람의 Pose를 추정하는 방법에 관한 연구입니다.
VNect의 전반적인 Flow는 다음과 같습니다.

우선, CNN을 기반으로 만들어진 모델을 사용하며 이는 ResNet50을 벤치마킹하여 설계된 모델입니다.
Image가 주어지면 해당 Frame에서 이전 Frame에서의 Key-Point를 사용하여 Bounding Box Tracking에 의해 추출된 Center에 있는 사람을 Crop 합니다. 쉽게 말해 이미지 속 중앙에 위치한 한 사람을 추출한다는 것입니다.
이후, Crop 된 Image로부터 ML NET을 이용해 모든 관절로부터의 2D Heat-Map과 3D 위치 맵을 예측 합니다. 그러고 나서 Filtering을 통해 Key-Point (각 관절 위치)를 조절합니다. 쉽게 말해 2D Pose를 추정하고 Dataset에서 제공하는 Z값을 통해 Image속에서 추출할 수는 없는 깊이 데이터를 예측하는 것입니다.
해당 결과 값은 Skeleton Fitting 과정을 통해 안정화된 Global Pose로 변환됩니다. 여기서 Global Pose는 Image 속의 좌표 체계가 아닌, 여러 좌표 체계에서 사용할 수 있는 것을 의미합니다. 또한 Skeleton Fitting은 관절 각도와 카메라 상의 Root 각도의 위치를 기준으로 계산하는 과정을 의미합니다.
한 층 깊게 들어가서, 사용되는 ML Model에 대한 내용은 다음과 같습니다.
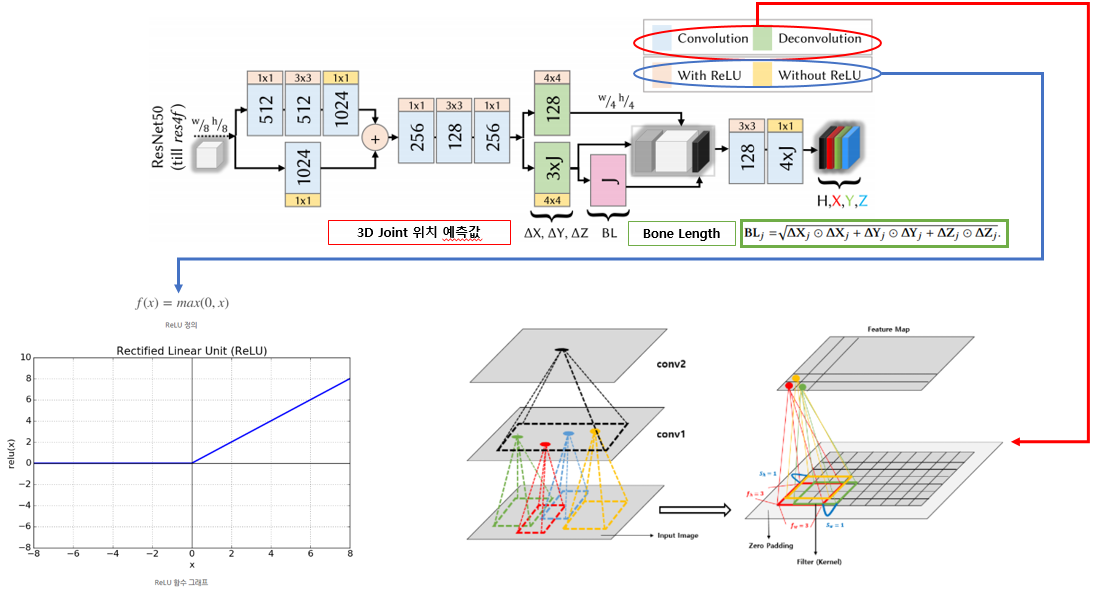
앞서 VNect은 ResNet50을 벤치마킹한 CNN 기반의 모델을 사용한다고 했습니다. 그래서 위 이미지와 같이 Convolution Layer가 여러 층 쌓인 모델을 사용합니다.
1x1 Convolution과 3x3 Convolution을 번갈아 가며 사용하고 ReLU 활성화 함수를 사용합니다. 또한 운동학적 상대적 3D 관절위치 예측 값($\Delta X, \Delta Y, \Delta Z$) 그리고 이러한 보조 작업들로 부터 구성된 뼈 길이 맵(BL)을 사용합니다. 이때 BL은 Root-relative Location Map인 $X_j, Y_j, Z_j$로부터의 Parent-relative Location Map $\Delta X_j, \Delta Y_j, \Delta Z_j$의 길이 값을 의미합니다.
간단히 말하면 이미지 속에서의 각각의 관절을 Convolution 연산들로 이루어진 Layer에서 Detection 하고 이는 각 신체 부위의 2D Position 값을 반환합니다. 그리고 이 2D Position을 토대로 Z값을 예측하여 3D 관절 위치를 반환합니다. 그리고 이 관절들의 변화량의 Distance를 계산하여 이를 각 Bone의 길이(= BL)로 추정하는 것입니다.
참고로 Convolution Layer란 Image에 행렬 형태의 Filter를 Convolution 연산하여 특징을 추출하는 과정을 수행하는 층을 의미합니다. 쉽게 말해 위 이미지의 오른쪽 하단 이미지처럼 큰 이미지가 있을 때 어떠한 뭉치 뭉치를 묶어 그룹화하여 합치는 연산을 통해 특징을 추출하는 것입니다. 이러한 과정을 여러 번 수행하면 이미지를 압축한 어떠한 특징을 추출할 수 있습니다. 반대로 추출된 특징에 Deconvolution 연산을 수행하면 특징을 추출하기 이전의 상태로 되돌아갈 수 있습니다. 물론 정말 똑같은 상태는 아니겠지만 말이죠.
그리고 추가적으로 ReLU 활성화 함수는 위 이미지의 왼쪽 하단과 같은 함수를 의미하며, 0보다 크면 입력한 값을 그대로, 0보다 작으면 0을 출력하는 함수입니다. 해당 함수는 0보다 작은 값들에서는 뉴런이 죽을 수 있다는 단점이 있지만 sigmoid, tanh 함수보다 학습이 빠르며, 연산 비용이 적고 구현이 간단하다는 면에서 Deep Learning에 많이 사용되는 활성화 함수입니다.
위와 같은 방식으로 VNect이라는 것이 만들어졌습니다. 그러나 이는 나름 15 FPS의 속도로 3D Pose를 추정하지만 여전히 빠르지는 않으며 결정적으로, 이미지의 중앙쯤에 위치한 한 사람만을 추적한다는 점에서 부족함이 있습니다.
XNect
Real-Time Multi-Person 3D Motion Capture with a single RGB Camera라는 Title을 가진 논문입니다.

앞서 다룬 VNect의 단점을 극복하기 위해 XNect이라는 것을 연구했다고 합니다.
결론적으로 같은 팀이 만든 것입니다.ㅎ 그래서인지 구현 방식이 달라지긴 했지만 비슷한 면도 많습니다.
어찌 되었든 이 XNect은 여러 명의 3D Pose를 거의 30 FPS의 속도로 추정한다고 발표하고 있습니다. 그렇다면 이는 어떻게 설계되었을까요?
XNect은 크게 3단계로 구성됩니다.

1단계에서는 SelecSLS라는 NET을 사용해 2D와 3D Pose를 추정합니다. 2단계는 간단한 Fully-Connected Network로 구성되며 검출된 사람들에 적용되고 Global 한 범위의 완전한 3D Pose를 재구성합니다. 3단계에서는 카메라와 관련된 위치 값 계산, 관절 각도 등을 계산하여 안정화된 결과 값을 제공합니다.
이제 각 단계에 대해 조금 세부적으로 다루어봅시다.
앞서 1단계에서는 SelecSLS NET을 사용하여 2D와 3D Pose를 추정한다고 하였습니다. 여기서 사용하는 SelecSLS는 ResNet50을 기반으로 설계된 모델입니다. 앞서 VNect도 ResNet50을 기반으로 만들었다고 했지요. 다만 이번에는 Model에 변화를 좀 주었답니다.
그 이유는, Pose Estimation에 있어 가장 많은 Computation Time을 소모하는 것이 이 1단계, 즉 Image에서 각 신체 부위를 Detection 하는 작업에 해당됩니다. 이를 경량화하지 않으면 Real-Time으로 3D Pose Estimation을 진행할 수 없습니다. 때문에 이의 경량화가 곧 FPS의 상승을 의미하며 이 부분이 핵심이라고도 할 수 있습니다.
SelecSLS는 다음과 같이 설계되었습니다. 명칭에서도 약간 예상할 수 있듯이 뭔가를 Select 한다는 것입니다.

SelecSLS는 모듈 내의 단거리 Skip 연결과 교차 모듈의 장거리 Skip 연결로 구성됩니다. Model의 디자인은 3x3 Convolution과 1x1 Convolution을 교차 배치한 것들로 구성되며 이는 Channel들의 혼합을 가능하게 한다는 특징을 가지고 있습니다. 또한 모든 Convolution들은 Batch Mormalization과 ReLU를 사용합니다. 이 부분은 VNect과 크게 달라진 건 없는 것 같죠.
핵심은 Skip에 있습니다. 위 이미지의 왼쪽을 보면, Layer의 출력이 반드시 다음 Layer에 연결되는 것은 아닙니다. 다다음 Layer에 연결되기도 하고 Module과 Module을 뛰어넘기도 합니다.
이렇게 수행하는 이유는 Skip을 함으로써 정확도 및 계산 속도를 높일 수 있기 때문입니다. 보통 ML에서는 뉴런과 뉴런 사이, Layer와 Layer 사이를 넘나들 때 미분 및 적분 연산을 진행합니다. 해당 연산은 곱셈과 나눗셈으로 구성되는데, 0이 연산에 포함되게 되면 이후부터의 연산은 모두 0이 되는 참사가 발생합니다. 이를 Vanishing이라고 하는데, 어찌 되었든, 보통 층이 깊을수록 정확도가 향상되고 층이 깊어지면 깊어질수록 Vanishing 될 확률이 늘어나겠지요. 이를 방지하고 좀 더 좋은 특징을 추출하기 위해 Skip을 사용합니다.
그냥 상식적으로 뭔가의 데이터를 쌓으면 쌓을수록 좋지 않을까 싶지만, ML에서는 적당한 데이터를 버리는 행위, 가끔은 연산을 넘기는 행위가 정확도 상승에 좋은 행위가 되기도 합니다. 우리의 뇌가 잠을 자기도 하고 과거의 데이터를 버리면서 계속해서 유지해 나간다는 점에서 비슷한 것 같기도 합니다.
참고로 위 이미지의 k는 Module안의 Convolution Layer들이 출력하는 특징 수를 의미하며, $n_0$는 Module의 출력 개수를 의미합니다.
위와 같은 1단계를 진행한 후 2단계로 넘어갑니다. 2단계에서는 3D Pose를 구성합니다. 아래 이미지에서의 k는 사람 index를 의미하고 c는 관절 Detection 정확도를 의미합니다. 그리고 $l_{j, k}$는 3D Pose Encoding을 의미합니다.
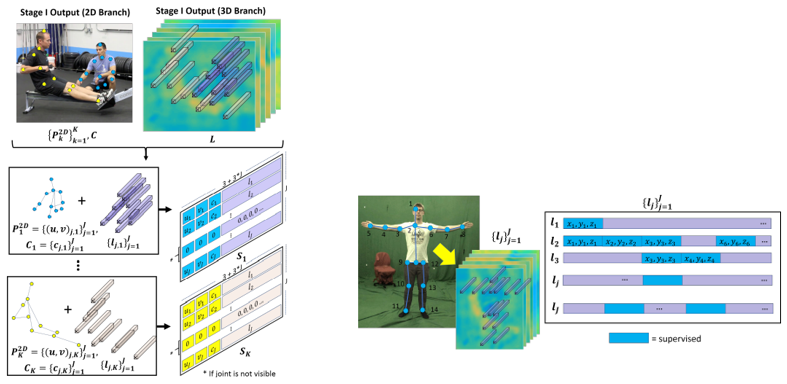
각 관절별로 3D Pose Encoding Vector인 $l_j$를 예측합니다. 그리고 이는 Kinematic Chain에 직접적으로 연결된 관절 j의 정보만 인코딩합니다.
예시적으로 설명하면, 1단계에서 각 관절 위치를 추정하면 위 이미지의 오른쪽 부분처럼, 각 x, y, z 값을 각 관절별로 처리합니다. 이때 관계된 관절들을 참조하며 계산합니다.
2번 관절의 경우는 1번, 3번, 6번 관절과 관련이 있습니다. 따라서 해당되는 관절들의 x, y, z 값을 supervised(= 감독)하여 하여 처리합니다. 이러면 관절들은 연결하며 Skeleton을 구성할 수 있습니다.
2단계에서 3D Pose를 구성하였으면 이제 마지막 단계인 3단계를 통해 좀 더 정확한 3D Pose로 가공합니다. 해당 단계는 Kinematic Fitting 과정이라고도 합니다.

Kinematic Fitting은 위 이미지의 가장 상단에 위치한 수식을 수행하는 것입니다. 이때 W 값들은 Parameter값으로 상수값입니다. 그냥 어떠한 가중치를 곱해주는구나 정도로만 생각하면 됩니다.
우선, 전반적으로 시간에 따른 사람의 형상을 추적하고 추론하는데, 이는 현재와 과거의 Frame으로부터 2D와 3D Pose를 추정한다고 생각하면 됩니다. 즉, 모든 수식은 현재 t와 과거 t-1로 구성됩니다.
또한 Image의 Pixel로부터 절대적인 cm의 3D 좌표를 추정하는 것은 어려운 작업입니다. 이를 위해서는 신체 부위의 상대적인 Bone의 길이를 계산하여야 합니다. 때문에 모든 수식은 Distance를 구하는 식으로 구성됩니다.
$E_{3D}$수식부터 보면, 정방향기구학에 의해 예측된 Skeleton의 Root-Relative 관절위치와 예측된 Root-Relative 3D 관절위치 사이의 차이를 구합니다.
생소한 명칭이 있습니다. 이부터 알고 가자면, 정방향기구학은 로봇기구학에서 파생된 명칭입니다. 우선 로봇기구학은 로봇에서 고려되는 링크의 위치, 속도 및 가속도의 관계를 다루는 학문으로 정방향기구학은 주어진 Joint 변수에 대하여 로봇 말단부의 위치/자세를 결정하는 과정을 의미합니다. 위 이미지의 오른쪽 이미지와 같이 로봇팔의 움직임을 구현하기 위해서는 말단부와 링크의 위치를 추정하는 연산이 필요하다고 합니다.
결론적으로 실제 세상에서의 관절위치와 추정된 관절위치의 Distance를 구한 것이 $E_{3D}$입니다.
$E_{2D}$ 수식은 예측된 2D 좌표에 Projection 연산을 수행한 것입니다. Image속에서 추정한 2D Pose 좌표이기 때문에 실제 세상과의 좌표 체계가 다릅니다. 또한 Camera 자체의 왜곡도 존재합니다. 이를 완화하기 위해서 World 좌표 계의 절대적인 위치를 재구성하는 Projection(= 투영) 연산을 진행합니다.
$E_{lim}$ 수식은 해부학적 내용을 토대로 관절의 회전 제한을 두어 제약을 가하는 연산입니다. 관절의 각도가 Min값 보다 작을 경우에는 min값과 추정된 각도 값의 차이만큼, Max값보다 클 경우에는 추정된 각도 값과 max 값의 차이만큼, 그 이외에는 0 값을 가중치로 줍니다. Neural Network는 관절의 위치만 추정하고 각도는 추정하지 않기 때문에 생체 역학적으로 제약을 주어야 합니다. 이를 위한 식이 $E_{lim}$입니다.
마지막으로 $E_{temp}$ 수식은 Neural Network가 각 Frame을 기반으로 Pose를 추정하기 때문에 일시적으로 불안정한 값이 나타날 수 있기 때문에 추정된 자세의 시간적 안정성을 주기 위해 $E_{temp}$연산을 수행합니다. 또한 $E_{depth}$ 수식은 Smoothness의 수식으로 깊이 방향을 변화에 페널티를 추는 식입니다.
간단히 말하면 $E_{temp}$는 중간에 Skip 될 수 있는 Frame으로 인한 추정값의 튀는 값을 완화하기 위해 이전의 각도 값과 현재의 각도 값의 최소 값을 가중치로 주는 것이고 $E_{depth}$은 추정되는 각도의 z 값을 이전과 현재의 값의 차이만큼의 가중치를 주는 것입니다.
복잡하다고 하면 복잡하고 간단하다면 간단할 수 있는 ML 모델에 대한 설명이었습니다. VNect에 추가적으로 단계 3이 추가되었다고 합니다. 특히 관절의 각도에 대한 필터가 말이죠. 때문인지 정확도도 VNect에 비해 상승되었다고 합니다.
하지만 이러한 XNect도 한계점은 존재합니다. 한계점은 다음과 같습니다.
- Multi-View Capture Algorithm의 정확도 보다 낮습니다.
- Nect을 기준으로 사람을 Detection 하기 때문에 거의 다 보인다고 하더라도 Nect 자체가 보이지 않으면 Pose를 추정할 수 없습니다.
- 극도로 가까운 상호작용을 하는 경우에는 안정성이 떨어집니다.
- 비슷한 모습을 하고 있거나 극도로 모습이 변화할 경우 인식률이 떨어집니다.
- Learning-Based Estimation을 하고 있기 때문에 Training 된 Pose와 동떨어질 경우 인식률 및 정확도가 낮아집니다.
이렇게 VNect과 XNect에 대해 알아보았습니다.
기본적으로 모델 부분은 통상적으로 사용되는 Skip Connection, Conv, Deconv, Batch Norm, ReLU 등을 사용하였기에 아주 새로운 내용의 논문은 아닌 것 같았습니다. 다만, 각 관절의 결과 값을 조정하는 부분에는 신경을 많이 쓴 것 같습니다. 때문에 결과물은 생각보다 꽤 좋았습니다. 여전히... 목이 돌아가거나 꺾이는 현상은 발생하긴 합니다...ㅎ
아무튼, 이번 포스트는 이렇게 마무리하도록 하겠습니다!
PS. VNect을 코드로 구현하는 부분에 대한 내용은 다음 포스트를 참고해 주세요.
[Code] VNect
이번 포스트는 3D Pose Estimation과 관련된 VNect이라는 논문을 TensorFlow를 이용해 구현해 볼 것입니다. 우선, Pose Estimation과 VNect이라는 논문에 대한 내용은 다음 포스트를 참조해주세요. [Pose Estimation]
mj-thump-thump-story.tistory.com
PS. XNect을 코드로 구현하는 부분에 대한 내용은 다음 포스트를 참고해 주세요.
[Code] XNect
이번 포스트는 3D Pose Estimation과 관련된 XNect이라는 논문을 PyTorch를 이용해 구현해볼 것입니다. 우선, Pose Estimation과 XNect이라는 논문에 관한 내용은 다음 포스트를 참조해주세요. [Pose Estimation] 2D/3
mj-thump-thump-story.tistory.com
'Programming > Deep Learning Network' 카테고리의 다른 글
| [Code] XNect (0) | 2023.04.04 |
|---|---|
| [Code] VNect (0) | 2023.03.13 |
| [Code] MobileNet v1 (0) | 2023.03.08 |
| [Model] RefineDet (0) | 2023.03.06 |
| [Model] SSD (Single Shot Detector) (0) | 2023.03.02 |




댓글