Object Detection을 수행할 때, 많이 사용하는 Model 중 하나인 YOLO에 대해 작성해보고자 합니다.
우선, YOLO는 Joseph Redmon이 v1 ~ v3까지 개발을 진행하였고 이후 버전들은 꾸준히 다른 여러 개발자들에 의해 발표되고 있습니다. 각 버전에 대한 논문은 다음과 같습니다. (2023년 2월 기준으로는 YOLO v8까지 발표된 것 같습니다.)
- YOLO v1
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
- YOLO v2
YOLO9000: Better, Faster, Stronger
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2,
arxiv.org
- YOLO v3
YOLOv3: An Incremental Improvement
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3
arxiv.org
- YOLO v4
YOLOv4: Optimal Speed and Accuracy of Object Detection
There are a huge number of features which are said to improve Convolutional Neural Network (CNN) accuracy. Practical testing of combinations of such features on large datasets, and theoretical justification of the result, is required. Some features operate
arxiv.org
- YOLO v5
TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
Object detection on drone-captured scenarios is a recent popular task. As drones always navigate in different altitudes, the object scale varies violently, which burdens the optimization of networks. Moreover, high-speed and low-altitude flight bring in th
arxiv.org
- YOLO v6
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
For years, the YOLO series has been the de facto industry-level standard for efficient object detection. The YOLO community has prospered overwhelmingly to enrich its use in a multitude of hardware platforms and abundant scenarios. In this technical report
arxiv.org
- YOLO v7
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS and has the highest accuracy 56.8% AP among all known real-time object detectors with 30 FPS or higher on GPU V100. YOLOv7-E6 object detector (56 FPS
arxiv.org
- YOLO v8
GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite - GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
github.com
v8은 Ultralytics라는 회사가 라이선스를 가지게 되었나 보네요... 뭔가 여러 플랫폼과 협업이 잘 된 느낌입니다. v8은 아직 수정 중이며, 내용이 완료되는 대로 논문으로 발표할 예정이라고 합니다. (2023년 2월 23일 기준)
어찌되었든, 이제 YOLO에 대해서, 특히 v1에 대해서 다뤄보도록 하겠습니다.
YOLO가 등장하게 된 배경은, Single Neural Network에 기반합니다. 인간이 사물을 판단하는 부분을 생각해 보면 각자 볼 수 있는 시야 범위 안에서 어떤 종류의 물체가 어디에 있는지 바로 판단한다는 것을 생각해 볼 수 있습니다. 이처럼 YOLO는 인간의 시각 체계와 비슷하게 동작하게끔 Model을 구성하였습니다.
물체를 둘러 싸고 있는 Bounding Box와 그 Box 안에 물체의 종류를 동시에 예측하는 Regression 문제로 Image Detection 문제를 풀어냅니다. 이러한 일련의 과정을 표현하면 다음과 같습니다.

어떤 Input Image가 있으면 하나의 신경망을 통해 물체의 Bounding Box와 Class를 동시에 예측하게 됩니다.
YOLO의 모토는 "Simple is Fast and Accurate"입니다. YOLO의 장점을 정리하면 다음과 같습니다.
- 빠르다.
- 다른 알고리즘과 비슷한 정확도를 가진다.
- 다른 도메인에서 좋은 성능을 보인다.
그렇다면 이러한 YOLO가 어떻게 동작하는지에 대해 다뤄보도록 하겠습니다.
Unified Detection
앞서 언급했듯이 YOLO는 Image Detection을 하나의 신경망을 구성하여 회귀 문제로 정의한 것이라고 하였습니다. 그렇다면 회귀 문제를 어떻게 최적화했는지 그 과정을 보면 다음과 같습니다.
Input이 있으면 적절한 Model을 구성해 Output을 내고 그 Output과 Label간의 Error를 담고 있는 Loss를 계산합니다. 그 Loss를 최소화시키기 위해 최적화 알고리즘을 통해 Loss가 최소가 되도록 Model안에 있는 Parameter(= Weight)들을 Update 시키는 과정을 반복합니다.
따라서 다음과 같이 학습하기에 앞서 문제를 풀기 위한 적절한 Model과 Ouptut, 그리고 Loss Fuction을 설정해야 합니다.
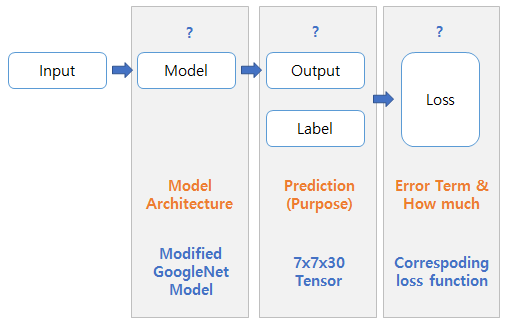
YOLO의 경우 Model은 GoogleNet을 조금 변형하여 사용하였고 Ouptut은 Bounding Box에 대한 정보와 Class 확률 그리고 그에 맞는 적절한 Loss Function으로 구성되었습니다.
Model Design

GoogleNet을 변형하여 Model을 구성하였으며, 24개의 Convolution Layer들로 구성됩니다. 앞의 20개의 Conv Layer는 GoogleNet의 구성과 동일하고 3x3만 쌓는 대신 1x1 Reduction Conv Layer를 몇 개 추가하였습니다. 그리고 4개의 Conv Layer를 더 쌓았습니다. 마지막으로, 예측해야 할 Output을 만들기 위해 2개의 Fully Connected Layer를 쌓았습니다.
출력 Tensor의 형태는 S(Grid)와 B(Bounding Box) 그리고 C(Class)에 의해 결정됩니다. 해당 식은 다음과 같습니다.
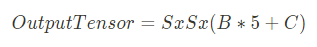
Model이 예측해야 할 출력 값은 Class 확률과 Bounding Box에 대한 좌표와 Bounding Box의 확률입니다. 해당 부분에 대한 자세한 내용은 다음과 같습니다.
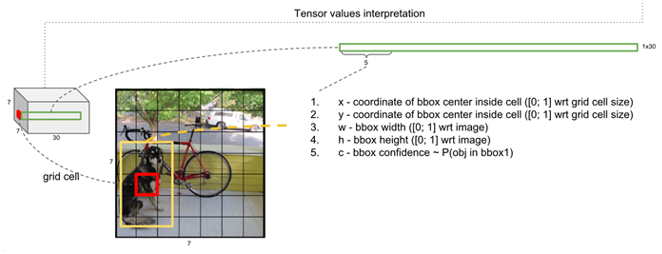
전체 이미지를 SxS로 나눈다고 생각했을 때, 총 SxS의 Grid Cell이 생성됩니다. 각 Grid Cell 안의 x, y 좌표와 w, h Bounding Box의 폭과 높이, c Bounding Box의 Confidence Score를 예측하게 되는데 이러한 5개의 예측 값을 B개의 Bounding Box 개수만큼 만들어주어야 합니다. 이를 정리하면 다음과 같습니다.
- 전체 이미지를 SxS로 나눕니다.
- 나눈 각 Grid Cell 영역에는 (x, y, w, h, c) * B 만큼의 예측 값이 필요합니다.
- x는 Bounding Box 중심의 x좌표 ([0,1]로 normalize, Grid Cell의 좌측 상단 x값을 더해주면 원래 좌표가 나오므로)
- y는 Bounding Box 중심의 y좌표 ([0,1]로 normalize)
- w는 Bounding Box의 폭 ([0,1]로 normalize)
- h는 Bounding Box의 높이 ([0,1]로 normalize)
- c는 박스의 Confidence Score로 Pr(Object) x IOU입니다.
- Pr(Object) x IOU는 물체가 있을 확률과 실제 물체의 Bounding Box와 얼마만큼 겹치는지에 대한 값과의 곱입니다. 여기서 IOU는 Intersection of Union으로 예측된 Bounding Box가 실제 Bounding Box(= truth ground value)와 얼마나 겹치는지를 계산한 값입니다.
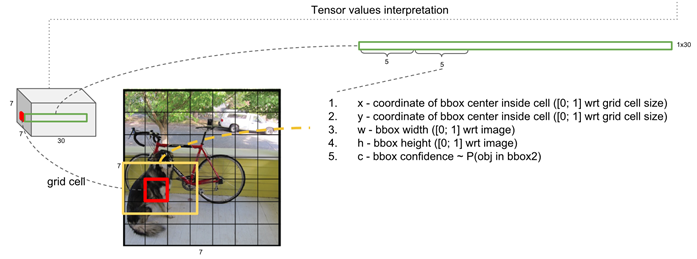
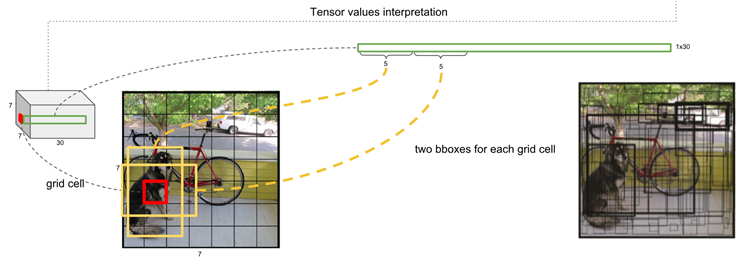
우측에 있는 이미지처럼 S=7, B=2일 때는 S x S x B = 7 x 7 x 2 = 98개의 서로 다른 Bounding Box의 값들을 예측하게 됩니다. 하단의 우측 이미지처럼, Box 영역이 두꺼울수록 더 높은 Confidence Score를 가지게 됩니다.
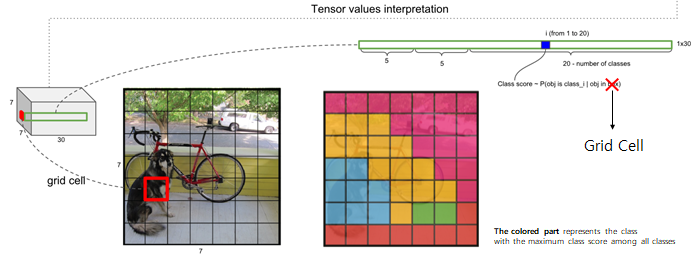
어떠한 영역에 대한 Class를 판단할 때, Bounding Box의 중심 좌표가 들어 있는 Grid Cell에서 판단하게 됩니다. 위 이미지에서 C=20, 즉 총 20개의 Class를 예측하는 문제이고 각 Grid Cell 하나 하나는 20개의 Class에 대한 예측 값을 가지게 됩니다. 위 이미지에서 중앙 그림을 보면, Grid Cell을 여러 가지 색으로 구분하였는데, 서로 다른 색은 서로 다른 Class이고 각 Grid Cell에서 가장 높게 예측된 Class를 표현하면 아래와 같을 것입니다.
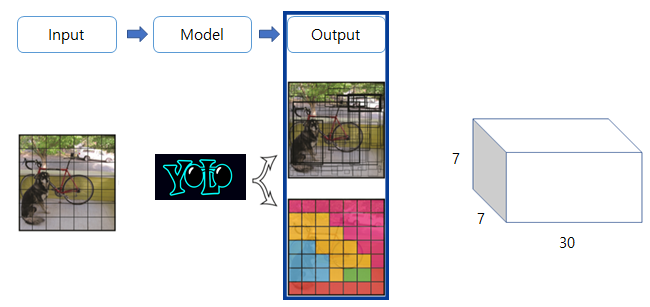
예측한 출력 값은 S x S x (B*5 + 20)으로 구성된 Tensor이며 위의 예제에서는 S=7, B = 2로 총 7 x 7 x 30의 Tensor가 출력 됩니다.
Loss Function
우선, YOLO에 사용된 Loss Function은 아래 이미지의 좌측과 같으며 각 Loss Term들을 분류하면 아래 이미지의 오른쪽과 같습니다.

Loss Term들을 분류하면, Bounding Box의 위치와 크기에 대한 Term, 해당 Grid Cell에 Object가 있는지 없는지에 대한 Loss Term 그리고 Class에 대한 Loss Term으로 나눠 생각할 수 있습니다.
위 식들을 자세히 살펴보면 다음과 같습니다.
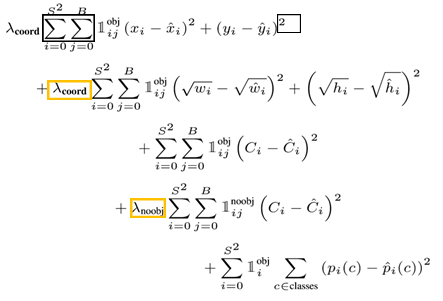
- 검은색 영역 : 최적화하기 쉬도록 Sum-Squred Error로 구성
- 노란색 영역 : Object가 있는 것과 없는 것 간의 차이를 둡니다. λcoord=5,λnoobj=0.5
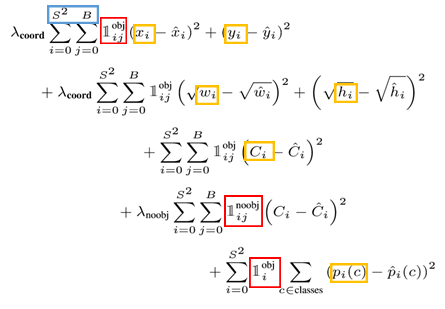
- 파란색과 노란색 영역 : Grid Cell과 Bounding Box의 개수
- 빨간색 영역 : \Iotaobjij은 Object가 있는 i번째의 Grid Cell에 j번째 Bounding Box이고 \Iotaobji는 Object가 있는 i번째 Grid Cell입니다.
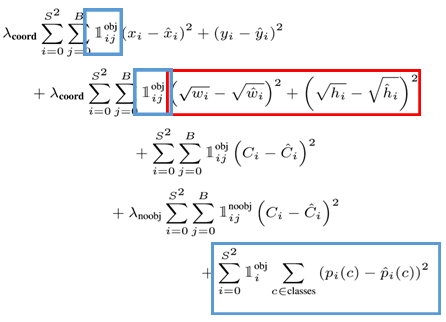
- 빨간색 영역 : 큰 Box와 작은 Box의 부분을 제곱해 주면 작은 Box는 큰 Box에 비해 더 작아지므로 이를 상쇄시키기 위해 루트를 씌어준 다음 제곱해 줍니다.
- 파란색 영역 : 물체가 없는 곳에서는 Class 확률과 Bounding Box의 크기를 더 이상 고려할 필요가 없기에 물체가 있는 영역에서만 Bounding Box에 대한 Loss Term과 Grid Cell의 Class 확률에 대한 Loss Term을 고려합니다.
Training
앞서 다룬 내용들과 같이 Model과 Loss Function을 구성했으면, 다음으로는 Train과정을 수행해야 합니다. YOLO는 앞의 20개의 Conv Layer를 Pre-Training 시킵니다. Training에 대한 전반적인 내용은 다음과 같습니다.
- GoogleNet 1000-class dataset으로 20개의 convolutioanl layer를 pre-training
- Batch size: 64
- Momentum: 0.9 and a decay of 0.0005
- Learning Rate: [0.001, 0.01, 0.001, 0.0001] ( 처음 0.001에서 서서히 감소시키다가 75 - epoch동안 0.01, 30 epoch동안 0.001, 마지막 30 epoch동안 0.0001)
- Dropout Rate: 0.5
- Data augmentation: random scailing and translations of up to 20% of the original image size
- Activation function: leaky ReLU (알파 = 0.1)
Testing
Training이 완료된 후 Test를 진행합니다. Test 시, 성능을 확인하기 위해 최종적인 Bounding Box를 예측해야 합니다.
우선, Output에서 예측된 Bounding Box의 Confidence Score와 Grid Cell의 Class Score를 곱하고 마지막으로 Non-Maximal Subpression 알고리즘을 통해 각 Object당 하나의 Bounding Box를 예측하면 됩니다. 이와 같은 내용을 좀 더 자세히 설명하면 다음과 같습니다.
다음과 같이 각 Bounding Box와 그 Bounding Box의 중심 좌표가 있는 Grid Cell의 Class Score 값들을 각각 곱합니다.
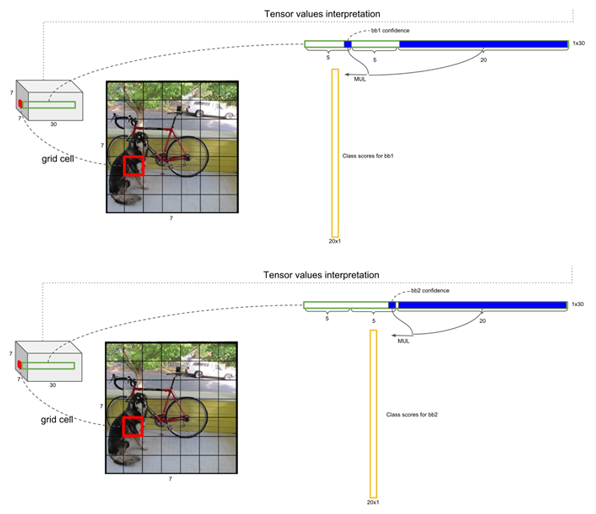
위 과정을 수행하면 다음과 같이 한 Grid Cell에는 2개의 Bounding Box의 Class 값들이 있는 20 x 1의 Vector들이 쌓이게 되고 최종적으로 B x (S x S) x C = 2 x 7 x 7 x 20 = 1440개의 값이 나오게 됩니다.
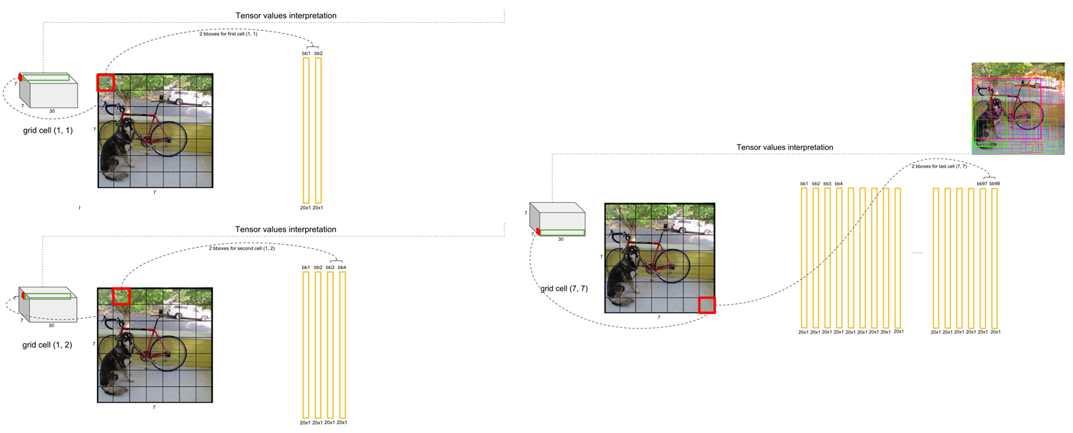
위 과정에서 나온 1440개의 값들에서 해당 물체에 하나의 Bounding Box가 선택되는 과정은 다음과 같습니다.
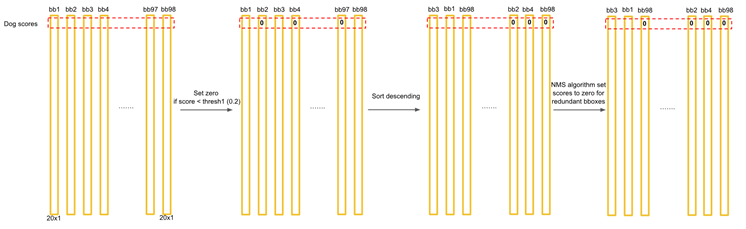
우선, Threshold 값으로 0.2를 지정하고 해당 값이 0.2 보다 적은 결과에 대해서는 모두 0으로 만듭니다. 이후, 내림차순으로 정렬을 하고 NMS 알고리즘을 통해 최종적인 Detection Output을 만듭니다.
NMS(= Non-Maximal subpression)은 다음과 같이 동작합니다.

첫 반복에서 Class 별로 가장 높은 값을 가지는 Bounding Box의 값을 bbox_max라고 하면, bbox_max와 현재 비교하고 있는 bbox_cur의 IOU를 계산하고 이것이 0.5보다 크면 같은 물체를 다른 Bounding Box로 예측하고 있다고 판단하고 bbox_cur의 값을 0으로 만들어 줍니다. 만일 IOU가 0.5보다 크지 않다면 그냥 놔둡니다. 이러한 과정을 반복합니다.
결과적으로 위의 과정이 끝나면 0 값이 많이 만들어지게 됩니다.

각 Bounding Box에 대해서 가장 크게 예측되고 0보다 큰 Class만 찍어주면 위와 같은 결과가 나오게 됩니다.
Conclusion
YOLO의 장점은 빠르고 정확하고 다른 도메인에서도 작동이 잘 된다는 것입니다.
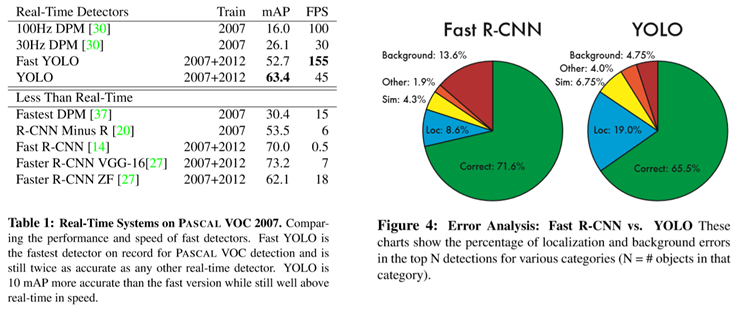
다른 알고리즘과 정확도(mAP)가 비슷하면서도 훨씬 빠르며 Background error가 fast R-CNN에 비해 현저히 낮습니다. 또한 fast R-CNN과 결합하면 더 좋은 성능을 보입니다.
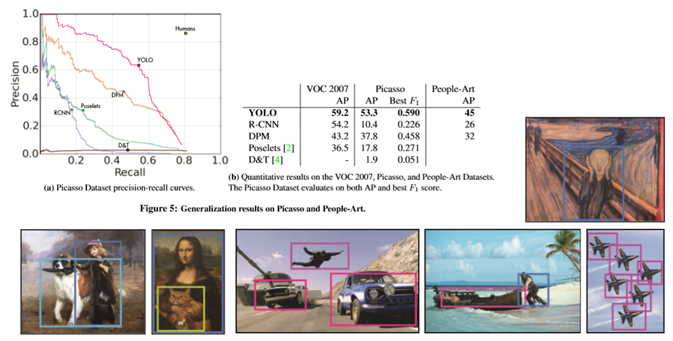
Art 작품에서 Detection을 수행해 보면 다른 알고리즘보다 훨씬 좋은 성능을 보인다고 합니다.
YOLO v1이 발표되었을 때가 2015년쯤이었는데, 그 당시에 대학교 선배님들이 졸업작품으로 YOLO를 이용하는 경우가 꽤 많았죠...ㅎ 그만큼 센세이션 했었는데 벌써 v8까지 나왔네요.
고양이랑 개만 분류해도 "오~" 했었는데, 지금은 그림도 그리고 작곡도 하고 글도 쓰고 코딩도 하고...

아무튼, YOLO v1은 이 정도에서 마무리하도록 하겠습니다.
현재 발표되고 있는 버전들은 초기 모습을 많이 벗어났다고 들었는데, 기회가 된다면 버전별로 정리해 보도록 하겠습니다.
여기서 마무리하도록 하겠습니다.
'Programming > Deep Learning Network' 카테고리의 다른 글
| [Model] RefineDet (0) | 2023.03.06 |
|---|---|
| [Model] SSD (Single Shot Detector) (0) | 2023.03.02 |
| [Model] R-CNN (0) | 2023.02.23 |
| [Model] FPN (0) | 2023.02.22 |
| [Model] RetinaNet (0) | 2023.02.22 |




댓글