이전 포스트에서 Tesseract를 이용하여 OCR을 수행했습니다.
깨끗한 이미지에서는 OCR이 제대로 수행되었지만 실생활에서 사용되는 이미지들에서는 OCR이 제대로 수행되지 않았습니다.
이번 포스트에서는 전처리 과정을 수행하여 OCR이 제대로 수행될 수 있도록 해볼 예정입니다.
우선, Tesseract를 통해 간단이 이미지를 OCR 해보았던 이전 포스트는 다음과 같습니다.
[OCR] [Tesseract - 2] Python 환경에서 Tesseract 예제 수행
앞서 OCR 수행을 위한 Tesseract 설치를 수행했습니다. 이번 포스트에서는 실제로 Tesseract를 이용해서 OCR를 수행해 볼 것입니다. 우선, Tesseract가 준비되어 있지 않다면, Tesseract 실행을 위한 환경 조
mj-thump-thump-story.tistory.com
이제 본격적으로 포스팅을 시작하겠습니다.
이번 포스트에서는 다음과 같은 영수증 이미지를 OCR을 해볼 것입니다.

상황을 가정하기 위해 영수증이 기울어지게 만들었습니다. 그리고 배경이라 판단되는 색상을 채워주었습니다.
전처리 과정을 수행할 것인데, 이 전처리는 Input 될 Image를 마치 종이 문서를 Scanner를 통해 Scan 한 것과 같은 결과물로 만들어내는 과정을 수행하는 것입니다. 전처리가 완료된 결과물은 대략적으로 다음과 같을 것입니다.

전처리는 다음과 같은 방식으로 수행할 수 있습니다.
우선, 사용할 모듈은 다음과 같습니다. 모두를 import 해줍니다.
import cv2
import imutils
from imutils.perspective import four_point_transform
import pytesseract
[IF Error Occured]
[Error 해결]
만일 ModuleNotFoundError(= "ModuleNotFoundError: No module named '~")가 발생할 경우, Error 메시지에 따라 필요한 모듈을 설치하면 됩니다.
다만, 아마도 scipy나 imutils 모듈이 미설치되어 있을 것이므로 다음과 같은 명령어로 설치해 줍니다.
>> pip install scipy
>> pip install imutils
이제, Original Image를 Load 하고 Show 합니다.
url = "ocr_receipt.PNG"
original_img = cv2.imread(url)
cv2.imshow("original image", original_img)
Original Image의 Size를 width=500으로 맞춰주고 BGR Format을 Gray로 변환합니다. 그리고 Blurr처리를 통해 Image의 잡음을 제거하고 잡음을 제거한 Image에 Canny를 적용하여 Edge를 추출합니다.
image = original_img.copy()
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5,), 0)
edged = cv2.Canny(blurred, 75, 200)
cv2.imshow("gray", gray)
cv2.imshow("blurred", blurred)
cv2.imshow("edged", edged)
이제 Canny를 적용한 Image에서 Contour를 찾아 영수증만을 추출할 수 있도록 해야 합니다.
참고로 Contour라는 것은 같은 Pixel Data 값을 가진 것을 연결한 선입니다. 보통 이미지의 외곽선을 검출하기 위해 많이 사용합니다.
아무튼, 이러한 Contour를 이용해 영수증의 윤곽선을 찾기 위한 과정은 다음과 같습니다.
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
receiptCnt = None
for c in cnts:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
if len(approx) == 4:
receiptCnt = approx
break
if receiptCnt is None:
raise Exception(("Could not find outline"))
output = image.copy()
cv2.drawContours(output, [receiptCnt], -1, (255, 0, 0), 3)
cv2.imshow("Receipt Outline", output)Canny를 적용한 Image에서 Contour를 찾고, 찾은 Contour를 크기순으로 정렬하여 cnts에 저장합니다.
cnts를 읽으면서 arcLength()를 통해 외곽선의 길이를 계산하고 approxPolyDP()를 통해 외곽선을 근사화합니다. 이렇게 근사화한 결과 좌표의 개수를 통해 사각형인지 아닌지를 판단합니다. 만일 사각형이라면 해당 좌표 Data를 receiptCnt에 저장하고 Loop를 빠져나옵니다.
참고로 사용한 함수들의 관한 정보는 다음과 같습니다.
- output image, contours, hierarchy = cv2.findContours(input image, mode, method[, hierarchy=[, offset]]])
input image는 Contour를 찾고자 하는 이미지를 의미하며, mode는 외곽선 검출 모드를 의미합니다. cv2.RETR_EXTERNAL은 Contours Line 중 가장 바깥쪽 Line만 찾는 것을 의미하며, cv2.RETR_LIST는 모든 Contour Line을 찾지만 Hieracy 관계는 구성하지 않는 것, cv2.RETR_CCOMP는 모든 Contours Line을 찾고 Hieracy 관계는 2-Level로 구성하는 것, cv2.RETR_TREE는 모든 Contours Line을 찾고 모든 Hieracy 관계를 구성하는 것을 의미합니다.
method는 외곽선을 근사화하는 방법을 의미하며, cv2.CHAIN_APPROX_NONE은 모든 Contour Point를 저장하는 것을 의미하며, cv2.CHAIN_APPROX_SIMPLE는 Contour Line을 그릴 수 있는 Point만 저장하는 것입니다. cv2.CHAIN_APPROX_TC89_L1과 cv2.CHAIN_APPROX_TC89_KCOS는 Contour를 찾는 알고리즘을 의미합니다.
- retval = cv2.arcLength(curve, closed)
curve는 외곽선의 좌표를 의미합니다. closed는 값이 True일 경우는 폐곡선을 의미합니다. 반환되는 값인 retval은 외곽선의 길이를 의미합니다.
- approxCurve = cv2.approxPolyDP(curve, epsilon, closed, approxCurve=None)
curve는 입력 곡선의 좌표를 의미합니다. epsilon은 근사화의 정밀도를 조절하기 위한 값입니다. 보통, 입력 곡선과 근사화 곡선 간의 최대 거리(= cv2.arcLength(curve)*0.02)를 사용합니다. closed는 값이 True일 경우는 폐곡선을 의미합니다. 반환되는 approxCurve는 근사화된 곡선의 좌표를 의미합니다.
이제 저장한 receiptCnt를 이용해 영수증만 추출하고 추출된 결과 이미지를 Tesseract에 넣어 OCR을 수행하면 됩니다. 다음과 같은 과정을 통해 수행할 수 있습니다.
ratio = original_img.shape[1] / float(image.shape[1])
receipt = four_point_transform(original_img, receiptCnt.reshape(4, 2) * ratio)
cv2.imshow("Receipt", receipt)
options = "--psm 4"
text = pytesseract.image_to_string(cv2.cvtColor(receipt, cv2.COLOR_BGR2RGB), config=options)
print("[RESULT] OCR with Tesseract :")
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
print(text)
print("<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")우선, receiptCnt는 (4, 1, 2)의 Shape를 가지고 있습니다. 외곽선 Position을 통해 이미지를 Crop 하기 위해서는 (4, 2)의 Shape로 변환해주어야 합니다.
이때 앞서 Original Image를 width=500로 Resize 하였기에 receiptCnt의 좌표 값도 Resize 해주어야 하기에 Original Image와 Resize 된 Image사이의 Ratio를 계산하여 곱해줍니다.
그리고 Tesseract를 수행할 때, Option으로 "psm 4"를 줍니다. 이는 다양한 크기의 단일 텍스트 열을 가정하도록 하는 옵션입니다.
다음은 Receipt Outline대로 이미지를 추출한 결과입니다.

영수증의 Outline을 잘 찾았고 해당 영역을 기반으로 영수증만 잘 추출할 수 있었습니다.
이제 이렇게 영수증만 추출된 이미지에서 OCR을 수행하면 다음과 같은 결과를 얻을 수 있습니다.
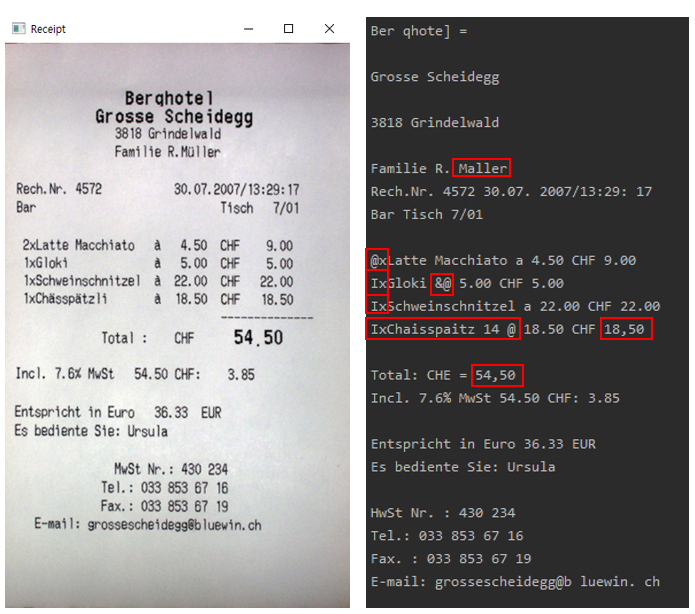
대체적으로 결과 값이 좋습니다. 위 이미지의 빨간 박스와 같이 잘 못 판단된 결과들이 있지만 어느 정도는 이해되는 오류 값들이라고 생각됩니다.
그런대로 제대로 수행되는 것을 보니 이전 포스팅 때보다는 더 나아진 것 같습니다. 그럼 이제, 이전 포스트에서 제대로 판단하지 못했던 이미지를 적용시켜 보겠습니다.
결과는 다음과 같습니다.

일단 번호판 추출은 제대로 수행되었습니다. 그러나 "가"를 "7"로 인식해 버렸습니다. 그러나 이전에 OCR 결과가 아무것도 반환되지 않았던 것보다는 훨씬 나은 결과임에는 분명합니다.
이제까지 약간의 Image Processing 과정을 수행하여 OCR 결과 값을 잘 반환하기 위한 과정을 수행해 보았습니다.
그러나 특정 상황에서만 잘 동작하거나 앞서 사용했던 이미지들보다 더 안 좋은 이미지들을 이용한다면 OCR이 제대로 수행될지 확실하지 않겠죠? 이를 위해 다음 포스트에서는 좀 더 다른 Image Processing 과정을 수행하여 OCR을 수행해 보도록 하겠습니다.
이번 포스트는 여기서 마무리하도록 하겠습니다!
후행 포스트 :
[OCR] [Tesseract - 4] Tesseract로 OCR 수행 후 특정 Text 추출
이전 포스트에서는 Contour를 통해 OCR하고자 하는 영역을 Crop 하고 OCR을 수행하도록 하였고 그런대로 좋은 결과를 얻을 수 있었습니다. 그러나 Image를 Text로 바꾸기만 하였을 뿐 Text Data를 딱히 이
mj-thump-thump-story.tistory.com
'Programming > Computer Vision' 카테고리의 다른 글
| [OpenCV] 특정 영역 지정 후 해당 영역에서 이미지 비교 (0) | 2023.02.02 |
|---|---|
| [OCR] [Tesseract - 4] Tesseract로 OCR 수행 후 특정 Text 추출 (0) | 2023.01.18 |
| [OCR] [Tesseract - 2] Python 환경에서 Tesseract 예제 수행 (0) | 2023.01.12 |
| [OCR] [Tesseract - 1] Tesseract Windows 환경에 셋업 (0) | 2023.01.12 |
| [SLAM] EuRoC를 이용한 ORB-SLAM3 테스트 (0) | 2023.01.11 |




댓글