이번 포스트에서는 STT(Speech To Text)를 이용함에 있어 Azure Service를 사용해보고자 합니다.

STT 서비스의 경우 Amazon, Azure, Google, IBM, Kakao, Naver 등 다양한 회사에서 다루고 있습니다. 모두 금액과 성능, 제공 API 등이 다릅니다. 이 중에서 Azure를 사용해볼 것입니다.
Azure는 12개월 동안 Free Trial Service를 제공합니다. 이를 이용하기 위해 체험 계정을 생성합니다. 다음 링크를 통해 체험 계정을 생성할 수 있습니다.
https://azure.microsoft.com/ko-kr/free/cognitive-services/
지금 Azure 체험 계정 만들기 | Microsoft Azure
12개월 체험 서비스, 항상 무료인 40개 이상의 서비스 및 200 USD 크레딧으로 시작하세요. Microsoft Azure에서 지금 체험 계정을 만들어 보세요.
azure.microsoft.com
회원가입 부분이니 이 부분 설명은 생략하겠습니다!
가입이 완료되었다면 본격적으로 서비스를 이용해보도록 하겠습니다.
회원가입한 정보대로 로그인을 한 후, Azure Portal에 들어갑니다.
https://azure.microsoft.com/ko-kr/services/cognitive-services/speech-to-text/
Speech to Text - 오디오를 텍스트로 변환 | Microsoft Azure
Azure Speech to Text와 더 편리하게 오디오 텍스트 변환 상호 작용을 할 수 있도록 앱 내에서 음성 오디오를 텍스트로 변환합니다.
azure.microsoft.com
Azure Portal에 들어가면 다음과 같은 페이지를 확인할 수 있을 것입니다. (Microsoft사의 웹페이지 업데이트로 인해 첨부된 이미지들과 조금 다를 수도 있습니다.)
Potal에서 구동을 진행하고 구독이 완료되면 구독 리스트가 뜰 것입니다.

이후, 다음 링크를 통해 음성 리소스를 만듭니다.
Microsoft Azure
portal.azure.com
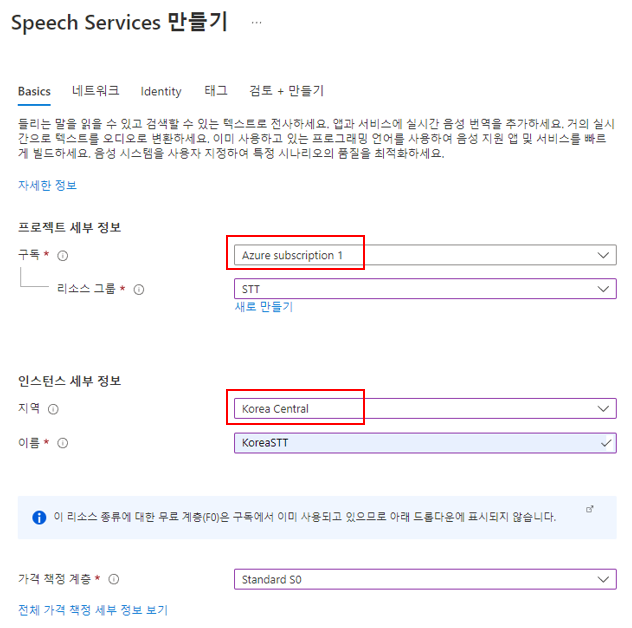
앞서 구독한 구독을 선택하고 리소스 그룹을 생성합니다. 그리고 지역은 Korea Central로 선택하고 가격 책정을 선택합니다. 이후, 네트워크, Identity, ... 등을 설정하고 생성을 마무리합니다.
생성이 마무리되면 리소스로 이동하고 이동하면, 다음과 같은 페이지가 뜰 것입니다.
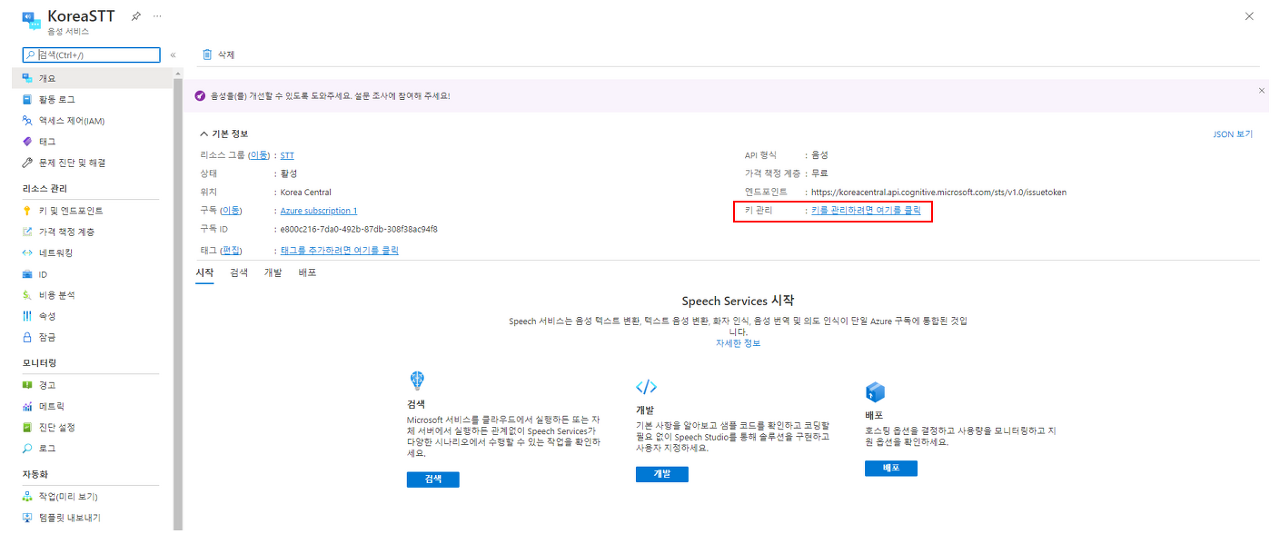

해당 페이지에서 Key 및 Region 정보를 얻을 수 있습니다. 이는 향후 작성할 코드에서 사용되는 데이터입니다.
위와 같은 과정이 마무리되었다면 이제, 프로그램 개발을 진행해야 합니다.
개발에 앞서, 개발을 위한 환경을 조성할 것입니다. 참고로 Python을 이용해 개발을 진행할 것입니다. (다른 언어도 제공하지만, 가장 간단하고 빠르게 구현할 수 있으니 우선 Python으로 개발해 봅니다!)
우선, Python을 설치합니다. 다음 링크에서 Python을 설치할 수 있습니다.
Download Python
The official home of the Python Programming Language
www.python.org
python 3.x Version을 설치합니다. 설치는 간단하니 설명은 생략하겠습니다.
Python 설치가 완료되었다면 이제, C++ Package를 설치합니다.
지원되는 최신 Visual C++ 재배포 가능 패키지 다운로드
이 문서에서는 최신 버전의 Visual C++ 재배포 가능 패키지 패키지에 대한 다운로드 링크를 나열합니다.
learn.microsoft.com
위 링크로 들어가 운영체제에 맞는 Package를 설치합니다. 이것도 그냥 설치하는 것이니 설명은 생략합니다.
설치가 완료되었으면, 다음과 같은 명령어를 Termial에 입력하여 Azure SDK를 설치합니다.
>> pip install --upgrade pip
>> pip install azure-cognitiveservices-speech
이로서 개발 환경은 모두 갖춰졌습니다. 이제 코드를 작성하여 실행시키는 일만 남았습니다.
우선, 다음과 같이 txt 파일에 Azure Data(Key, Region 값)를 작성해 놓습니다.
| ** 파일명 : Azure.txt ** 2412k4n12lkjlfv4jf (>> Key Value) koreacentral |
이 Text 파일을 Load 하여 Azure SDK와 연결할 때 사용할 것입니다. 이후, 마이크를 통해 음성 데이터를 Input 하고 Input 된 음성 데이터를 Text로 변환한 결과 값을 화면에 표시할 것입니다.
위와 같은 동작을 수행하는 코드는 다음과 같이 작성합니다.
우선, 사용되는 모듈은 다음과 같습니다.
#-*- coding:utf-8 -*-
import azure.cognitiveservices.speech as speechsdk
import osAzure와 File Read에 사용되는 모듈입니다.
다음은 저장한 Text 파일을 Read 하는 기능을 하는 함수입니다.
##### Read Azure Key and Region file #####
def readAzure() :
with open(os.getcwd() + '\Azure.txt', 'r', encoding='utf-8') as f:
txt_data = f.read()
data = txt_data.split('\n')
return data[0], data[1]
다음은 STT 부분 함수입니다.
##### STT #####
def speachTOtext(language_signal, key, region):
STT_result = ""
error_signal = 0
speech_key, service_region = key, region
language_code=""
if language_signal == "korean":
language_code='ko-KR'
elif language_signal == "english" :
language_code='en-US'
# STT with azure
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region, speech_recognition_language=language_code)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
result = speech_recognizer.recognize_once()
# Checks Result
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
STT_result = format(result.text)
error_signal = 0
elif result.reason == speechsdk.ResultReason.NoMatch:
error_signal = 1
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
error_signal = 2
if cancellation_details.reason == speechsdk.CancellationReason.Error:
error_signal = 3
# if language is english, then all letters change to lower letter
if language_signal == "english":
# change lower
STT_result = STT_result.lower()
# delete all other mark
STT_result = STT_result.replace(".", "")
STT_result = STT_result.replace("?", "")
return STT_result, error_signal언어는 한국어와 영어를 사용할 수 있도록 하였고 STT 수행결과와 Error 코드를 반환하도록 하였습니다.
Main 부분 코드는 다음과 같습니다.
#### main flow ####
if __name__=="__main__":
# read azure key and region
azure_key, azure_region = readAzure()
# input korean or english
language = ""
while True:
user_speak = "" # user's say
error_sig = 0
# STT
user_speak, error_sig = speachTOtext(language, azure_key, azure_region)
# STT success -> calculation the result
if error_sig == 0 :
print("User said : ", user_speak)
elif error_sig == 1 :
print("ERR_NOMATCH")
elif error_sig == 2 :
print("ERR_CANCEL")
elif error_sig == 3 :
print("ERR_CANCEL")Azure Data를 Load 하고 사용할 언어를 지정하고 Loop를 돌면서 사용자의 음성 데이터를 Read 합니다. 그리고 Read 된 음성을 분석하여 Text로 변환시키고 해당 결과 값을 출력합니다.
이 과정이 끝입니다.
정말 간단하게 STT를 수행할 수 있습니다. 물론 단점도 있습니다. 당연하겠지만, 흔하게 사용되지 않는 고유 명사의 경우 인식을 못합니다. 이 경우는 부분 학습을 시켜서 수행할 수 있도록 만들 수는 있습니다. (일부 서비스는 해당 기능을 제공, ex. Google)
가장 베스트는 필요한 스펙을 가진 STT를 직접 구현하는 것이겠지만, Dataset을 구성하고 Model 설계 및 구현하고 Train 시키고 반복하고...ㅎ 힘들다면 약간의 비용을 지불하는 것도 나쁘진 않을 수도 있겠죠?
STT를 다뤄보았다에 만족하고 요번 포스트는 여기서 마무리하도록 하겠습니다.
'Programming > Sound Analysis' 카테고리의 다른 글
| [Sound Cropper] 사운드 파일 속, 소리 구간 추출 (0) | 2023.03.24 |
|---|---|
| [Deep Learning] LSTM 예측 모델을 이용한 작곡가 프로그램 개발 (0) | 2023.02.08 |
| [Toolkit] 음악학에 활용되는 Music21 사용 방법 (0) | 2023.02.06 |



댓글